【Note】类型、不确定性与llm工程 - 内部分享草稿
"本文是我在我司内部研发进行分享的时候的内容草稿。这篇主要总结了一些我关于代码编写以及LLM工程上的不确定性的思考。"
引言
当我们凝视世界的时候,我们实际上获得的是什么东西?
让我们先从几个简单的例子讲起。
这是红苹果:

这是绿苹果:

那我们凝视这两个苹果的时候,我们能获得什么信息?
答案是显然的:苹果的颜色、苹果的种类(”这是一个苹果“)、苹果的大小......种种种种。
那么,红苹果与绿苹果相等么?或者说,我们可以构造红苹果与绿苹果的相等关系么?
答案取决于我们如何构造相等性。如果我们关心的是苹果的颜色,那么红苹果与绿苹果是不相等的;如果我们关心的是它是否是一个苹果(虽然不严谨,但可以说我们关心的它的物种),那么红苹果与绿苹果是相等的。
这样的情境可以推导到显示世界的许多事物上:山川河流万事万物。如果我们要构造相等性,我们需要寻找到一个可以构造相等性的量(metrics),这个量是我们在凝视世界的时候能够获取到的一段信息,或者说是我们所关心的信息。
例如,我们关心物体的运动情况如何,我们有平均速度、加速度这样的量,这样的量相等,我们可以说这两个物体的运动状况相等;我们关心不同生物之间的区别,于是便有了界门科属种这样的量......量是由人的观察框定的。
回到开头的问题上,一个显而易见的答案是:当我们凝视世界的时候,我们实际上获得的是我们关心的信息。飞鸟飞过天际,游鱼游于深渊,物质的世界永远是那个物质的世界,我们无法获得物质世界的本质(虽然这又是一个机械化的哲学命题,什么是本质呢?)——我们对世界的认识永远取决于我们关注什么。
计算机科学的可计算理论由图灵机与丘奇的 lambda 演算共同奠基。计算机科学解决的问题之一是如何计算我们在现实世界中能够得到的信息、从而去更好地利用信息可以提供的指导去改造世界的问题。于是我们就有了用于计算的程序,当我们想要解决的问题变得复杂起来——因为现实世界就是那么复杂——程序也变得不断复杂起来,如何更好地去组织程序、组织程序的合作开发的这个问题,又催生了软件工程。
不过今天我并不想讲一些比较庞大的开发方法论,而是回到一些比较简单原始的内容讲起:类型。
类型
编程语言的类型是一种自然而然便因为现实需要诞生的产物。首先,我们都知道,在我们目前熟知的计算机里,一切数据放到底层都是0与1构成的。人类要方便地使用自然语言去编写程序,于是在机器语言上诞生了汇编语言,汇编还是太原始了,于是就有了现有的编程语言。这是第一点,方便地编写程序的需求而铸就类型诞生的原因。其次,我们对世界的观察总是对客观世界的一种信息提取,观察下提取的信息总是结构化的信息,人对世界现实的观察总是可被结构化的,而编写程序是为了解决现实世界的问题,这是类型得以诞生的物质基础。
类型的意义是对数据(信息)进行约束。程序对信息(或者说是数据的类型)的计算,总是在更改这两样事物:
- 类型对应的实例的值。
- 类型本身(当然,类型也是一种值,但我们在这里先区分开来讲)。
以我们的日报的生成管道为例,让我们先不考虑其中的具体实现细节,摒弃掉工程化上的缓存、并发等等细节,其实它做的事情只是:传入关系型数据与非关系型数据,生成卡片内容与Web端的阅读内容。
+--------------------+ +-----------------------+ | 关系型数据 (Twitter) | | 非关系型数据 (长文本) | +--------------------+ +-----------------------+ | | | | v v +---------------------------------------------+ | 生成管道 | +---------------------------------------------+ | | v v +-------------------+ +--------------------+ | 卡片内容 | | Web端阅读内容 | +-------------------+ +--------------------+也便是:生成管道是 (关系型数据,非关系型数据)=>(卡片内容生成,Web端阅读内容生成) ,两个类型到两个类型的转换,这是类型的变化。同时,你传入的关系型数据与非关系型数据的不同,生成的对应的卡片内容与Web端内容也不同,类型变换前后,它们在计算机底层的数据也发生了变化,这是值上的变化。
然后,再让我们考虑里面的细节,例如数据进入生成管道,显然它要有一个过滤模块,该模块用于过滤掉我们不需要的数据,这个过滤模块便是:(关系型数据,非关系型数据)=>(过滤后的关系型数据,过滤后的非关系型数据) 的转换。
+--------------------+ +-----------------------+ | 关系型数据 (Twitter) | | 非关系型数据 (长文本) | +--------------------+ +-----------------------+ | | | | v v +---------------------------------------------+ | 生成管道 | | +---------------------------------------+ | | | 过滤模块 | | | +---------------------------------------+ | | | | | | v v | | +----------------------+ +----------------------+ | | | 过滤后的关系型数据 | | 过滤后的非关系型数据 | | | +----------------------+ +----------------------+ | | | | | v | | +--------------------------------------+ | | | 【...剩余模块】 | | | +--------------------------------------+ | +---------------------------------------------+ | | v v +-------------------+ +--------------------+ | 卡片内容生成 | | Web端阅读内容生成 | +-------------------+ +--------------------+之后的步骤其实就是思考数据的下一步根据我们的需要应该要进行怎样的处理,投入是什么、产出是什么,这样子根据我们的需求一步步去填充我们程序,我们的程序框架也就慢慢地搭起来了。在这里我简单推荐一下 string diagram 这种形式,你可以在书写你的程序时,以这样的图在草稿纸上绘制你的程序(也可以程序的某一个部分),帮助你去厘清自己的思考。
以下是如何做一个柠檬派的 string diagram。这种图,你可以以工业界的资源论的想法去看待:一切都是资源的投入与产出,投入给机器,机器消费后产出新的资源。
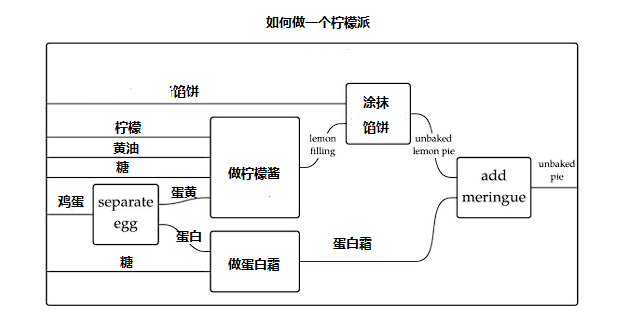
这种图比较美妙的地方在于,它能够为你理清楚哪些东西是可以复合在一起的,例如做柠檬酱与做蛋白霜,可以合并为【做预制品】这一个模块:
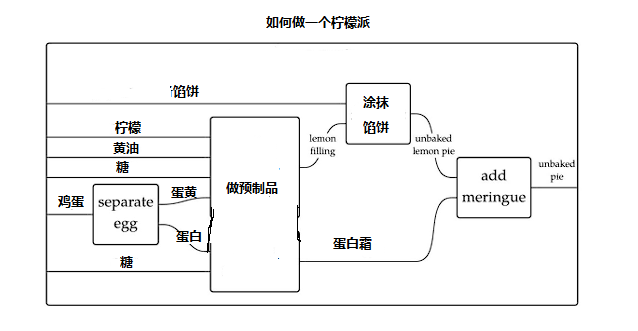
当然,回到前面讲, (关系型数据,非关系型数据) 这个形式,本身便可以认为是两种类型的积构成的新类型。不过这种东西细讲起来会扯到太多细碎的知识,所以在此按下不表。我们只需要记住:程序可以被视为类型与具体的值的转化,优先从类型变换的角度去构筑你的程序,你能省下很多心力。将程序视为对数据及其类型的变换计算,这也是我期望大家在开发中可以多做到的。
例如这段代码,它的做法是计算文章的嵌入,而后根据嵌入计算文章两两比较的相似度矩阵,最后通过相似度矩阵去对文章进行分组:
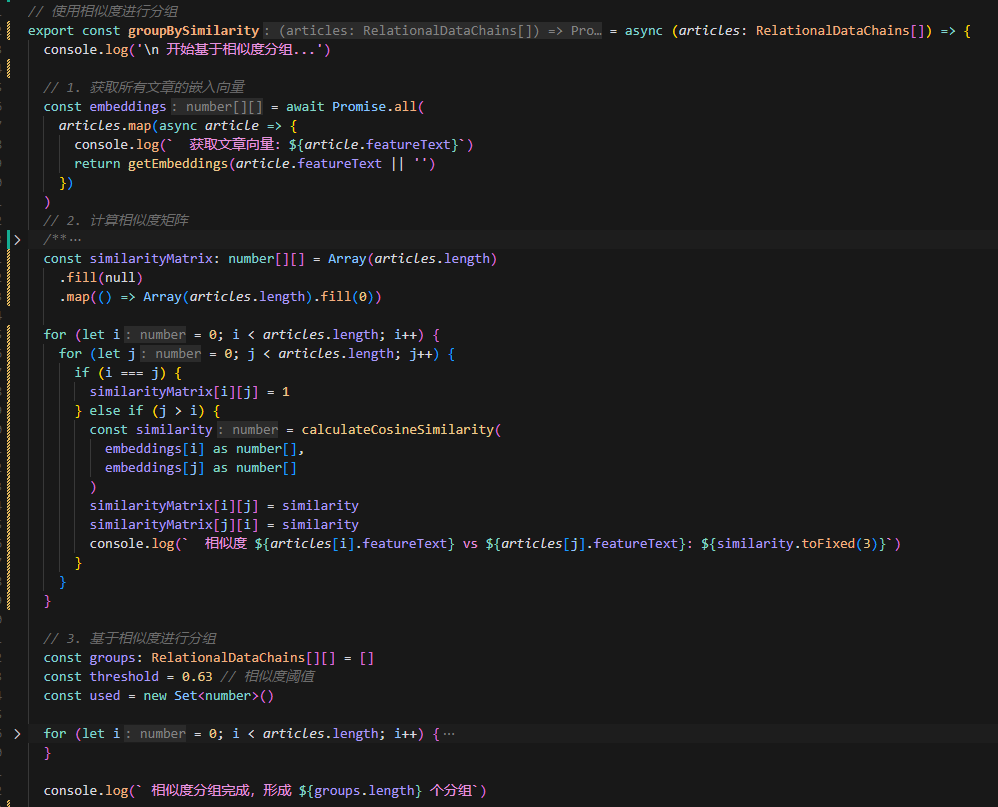
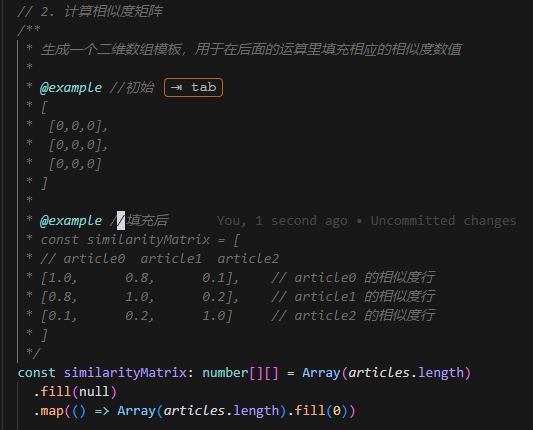
如果在没有 AI 辅助的情况下,这一系列的完成让人去写,显然是痛苦的,你的思考是细致的一步步的推导。数据如何转变的每一步细节在你写代码的时候就要细细考量。
即使现在有了AI辅助,阅读代码的人也是痛苦的,看代码的第一眼,你不清楚在每一层 for 循环里,究竟你用到了哪些变量,可能造成了哪些影响。
但是在写代码的时候,我们完全可以这样,把类型前后的变换封装在函数中,这样我们不仅能利用到函数名可以提供到的语义信息,还能够清晰地了解到前后用到了什么数据,数据之间发生了怎样的类型变换。

你可能觉得这是扯淡,觉得这样子阅读起来还是怪怪的,这是因为 typescript 并没有一个名为函数的天然 curry 化的特性,如果函数支持天然 curry 化,你可以遇见这样的代码:

一目从上向下扫过来,按顺序读取,代码执行逻辑一目了然。
我并非贬斥 for 循环以及命令式的语言,只是,多使用函数能够帮助你分割你程序的作用域,提升程序的可读性与维护性,不要总是把一连串的执行逻辑塞在一个函数里。例如这样的函数里的代码,即使有注释帮助,你第一眼真的看得懂么:
我们编写程序应当有一个 Type => Type 的心智模型,它能够帮助你更好地去理解与开发你的程序。
虽然如此,看起来程序就是一个巨大的 Type => Type => Type 的推导,那么,是什么让我们的程序开发总是容易遇到 Bug 与问题呢?
答案是:现实世界的复杂性带来的不确定性。
不确定性
编写程序是为了解决现实问题。但是现实世界是复杂的,计算机世界也继承了复杂世界的复杂性。程序运行可能会遇到各种问题:与数据库的连接失败、运行的宿主机的网线被拔了......种种种种。
解决现实问题是为了寻求到确定性的解,编写程序是为了寻求一个确定性的解,然而现实世界却总是不确定的。
例如这段代码:
await saveWechatResultToDatabase({ summaryId: wechatRecord.summaryId, // 假设你有记录的唯一 ID resultData: twitterIdsString, });它将微信数据保存到数据库中,如果在尝试保存的时候,它和数据库的连接崩溃了,那会怎样?
答案是:因为代码不会按预期完成任务,它会抛出异常。如果程序没有对异常进行处理,那么它会引发整个程序的崩溃。这是为了保证程序运行的正确性而做出的设计,是我们为了完成程序寻求确定性解的使命而付出的代价。
为了处理异常,编程语言中往往会提供 try-catch 这样的错误捕捉机制,让我们能够处理这种可能会引发程序崩溃的异常错误。
try { // saveWechatResultToDatabase 保存数据的函数 await saveWechatResultToDatabase({ summaryId: wechatRecord.summaryId, // 假设你有记录的唯一 ID resultData: twitterIdsString, }); customLogger.log(`微信记录 (ID: ${wechatRecord.id}) 的处理结果已保存到数据库`); } catch (error) { console.error(`保存微信记录 (ID: ${wechatRecord.id}) 的处理结果时发生错误:`, error); }但是,对于一些自身错误类型较为薄弱的语言而言,可能 try-catch 并不是很好用,因为我们不能捕捉到异常错误的具体信息:

虽然我们可以通过 instance of 这样的语句去对错误进行匹配处理,但是,程序如此复杂,我们总是可能遇到要多个 try-catch 去捕捉程序错误的情况:
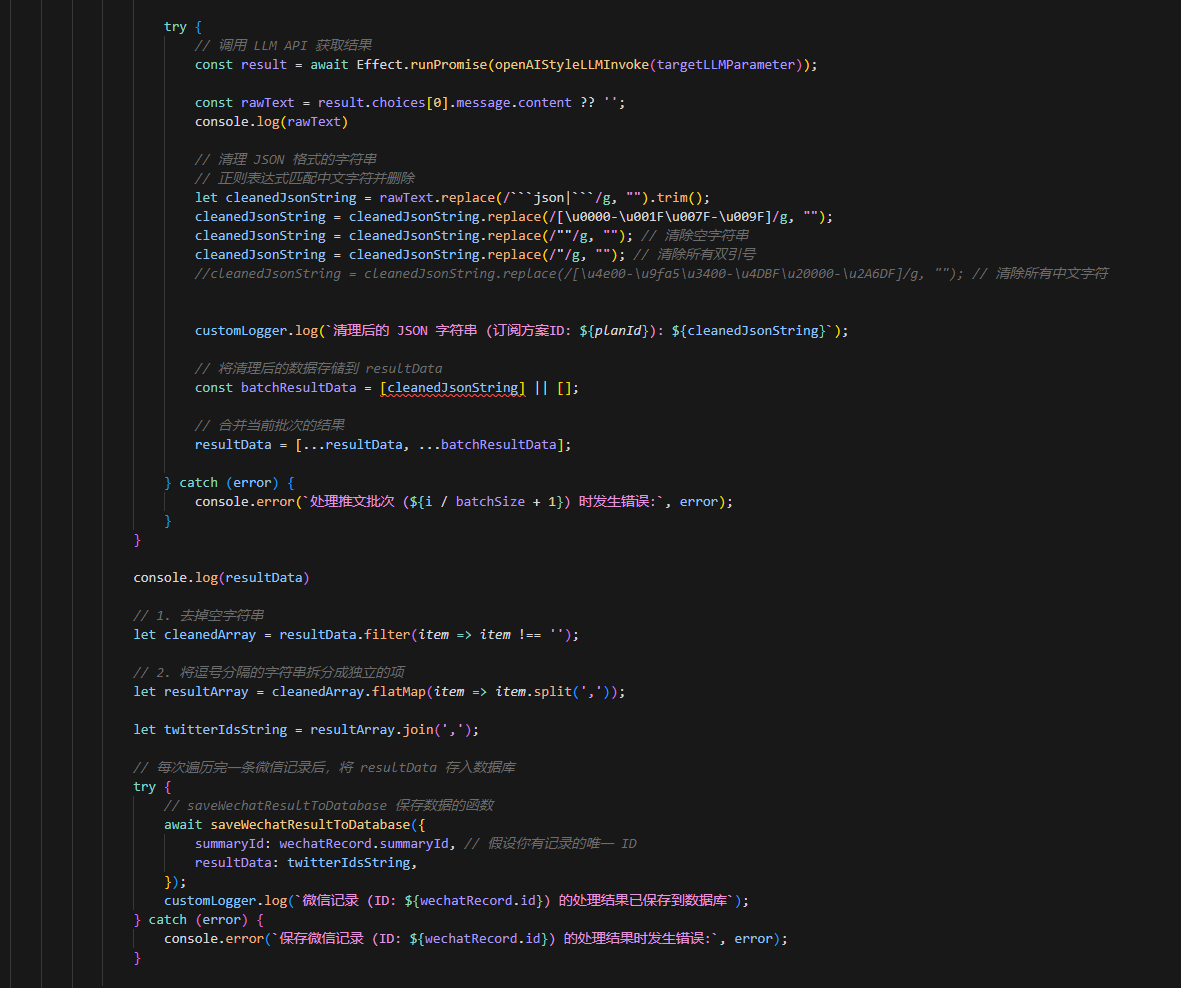
程序会变得非常复杂。并且,我们并不总是能记得对那些不确定的、包含副作用的、可能会引发异常的代码使用 try-catch 进行捕捉,倘若偌大的程序中有一处异常没有做处理,那么整个程序都会在那个异常发生时崩溃:
是的,我们可以预先分划好粒度,或以函数,或以类,将这些可能会引发错误的操作封装好:
export async function fetchResponse(url: string) { try { return fetch(url).then(res => res.json()) } catch (error) { console.error(error) return null }}但是,我们往往要同时用到多个可能会引发这样的错误的操作,其中可能前一个环节的操作结果会是下一个操作的输入:
export async function fetchResponse(url: string) { try { return fetch(url).then(res => res.json()) } catch (error) { console.error(error) return null }}
export async function postResponse(url: string, body: any) { try { return fetch(url, { method: 'POST', body: JSON.stringify(body) }).then(res => res.json()) } catch (error) { console.error(error) return null }}
async function main(url: string) { try { const response = await fetchResponse(url) const thePostResponse = await postResponse(url, response) return { response, thePostResponse } } catch (error) { console.error(error) return null }}这种情况下程序的复杂度会不断上升。并且,我们在函数签名里总是无法得到可能引发的错误的类型。着实很痛苦。
编写程序是与复杂的现实世界的搏斗。程序的编写,软件工程,它们做的事情其实就是一个:在解决问题的同时,消除解决问题路径上的不确定性。确立确定性,消弭不确定性,这便是软件工程的意义之一。
为了解决现实问题,为了与不确定性做搏斗,人们做了很多努力。例如面向对象编程的多种范式、例如函数式编程语言........种种种种。我在这里简单的概括一下这些做法确立下来的可以帮助你消弭不确定性的路子:
- 思考清楚问题解的边界条件。
- 将副作用进行隔离(作用域隔离)与引用透明。
- 让程序可维护,从而避免后续维护引发的问题。
EffectTS
EffectTS 这个库非常有意思,它的基础 Effect 类型,是对 可能包含副作用的计算 的抽象。它的类型为:
┌─── 代表计算成功的返回类型 │ ┌─── 代表计算可能的错误类型 │ │ ┌─── 代表计算可能要用到的外部依赖 ▼ ▼ ▼Effect<Success, Error, Requirements>因此,你可以用 Effect 这个抽象,去封装任何可能会发生副作用的计算,并且通过类型系统的签名得知它可能引发的异常错误:
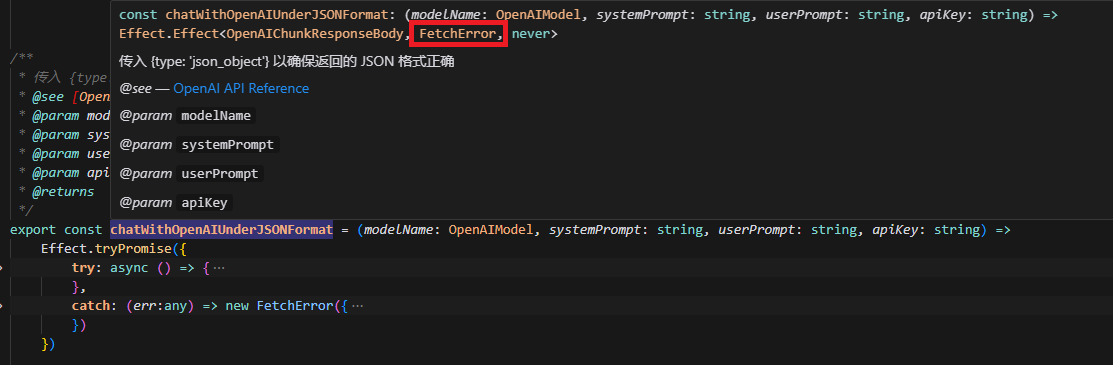
当你能够正确处理所有的预期错误后,代表错误类型的类型签名便是 never ,相当于提示你可以放心执行这段计算了,如果出错只可能是存在你没有考虑到的边界条件:

反之,则可以提醒你这个计算存在可能的错误,是需要你额外处理的。
你可以使用 Effect 这个类型去封装你的一切操作,无论是异步的、还是同步的:
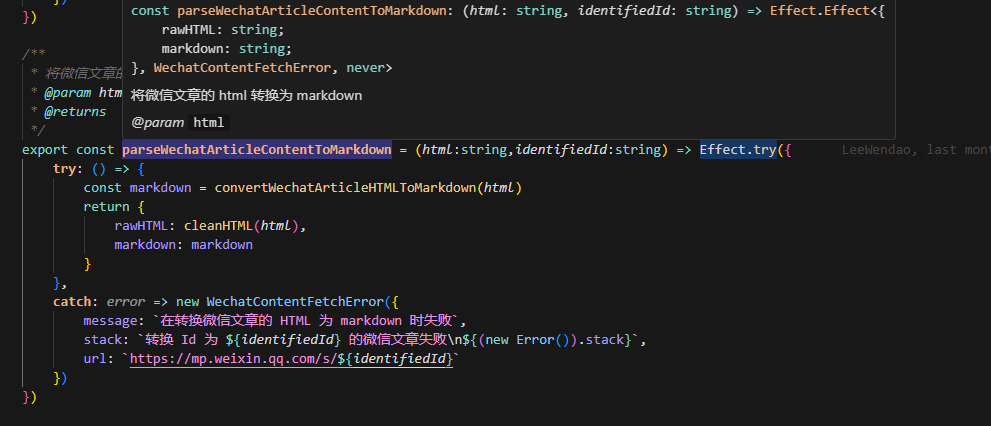
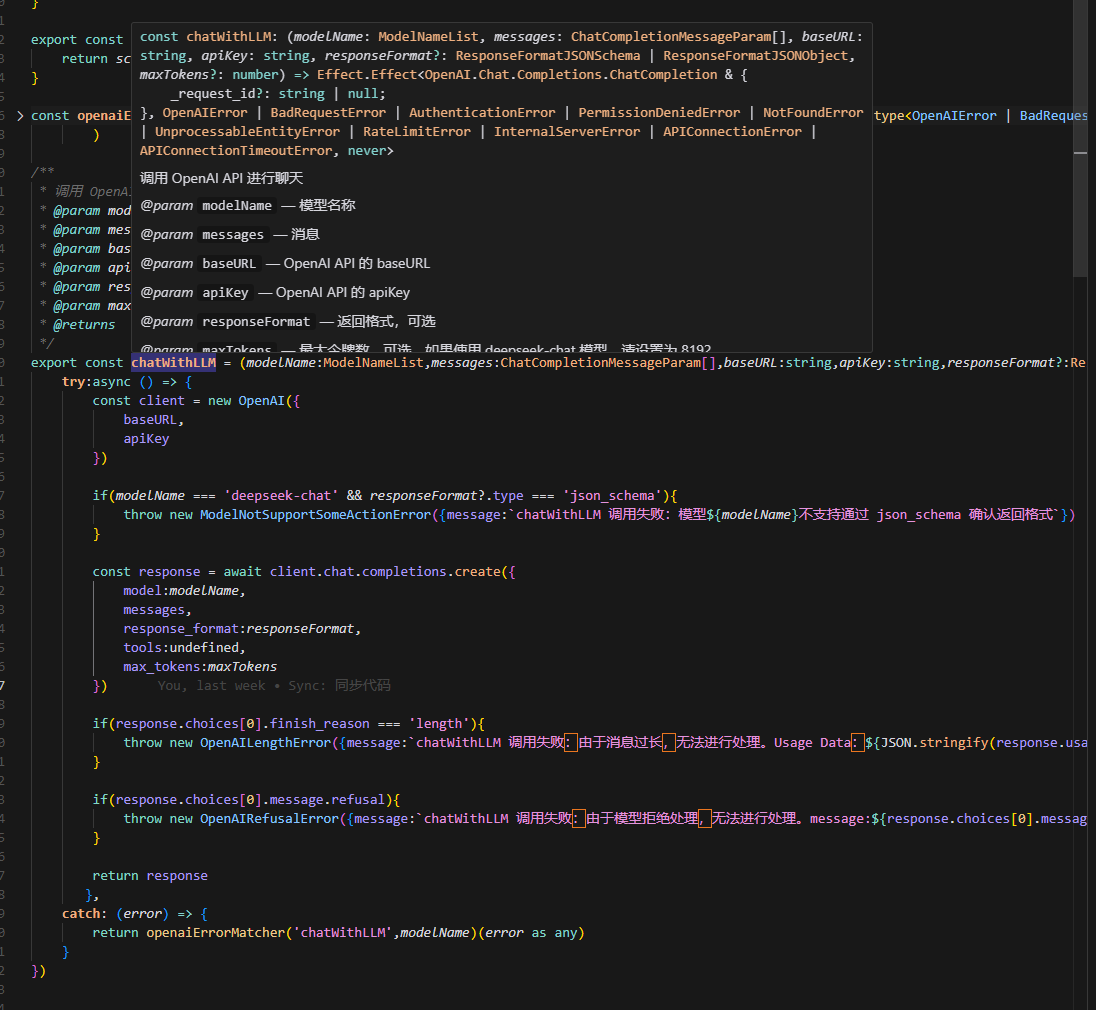
它厉害的地方在于,只要封装成了 Effect ,无论你的操作是异步的还是同步的,都是可组合的:
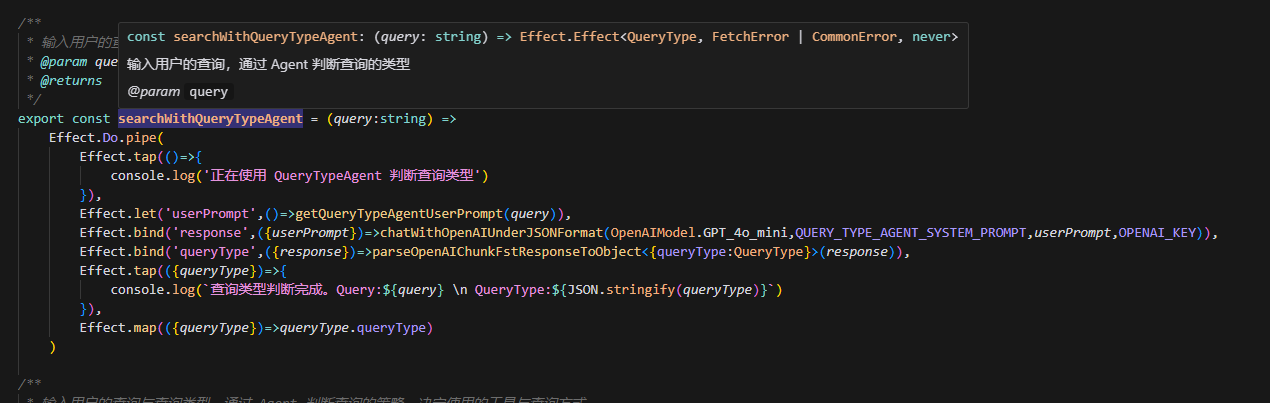
对比 Promise ,自由度高得很多。例如,它只是在描述计算,而不是执行计算,但是 Promise 在创建得时候就会被兑现:
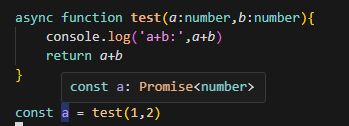

而 Effect 是声明式地创造一个 Effect 类型:
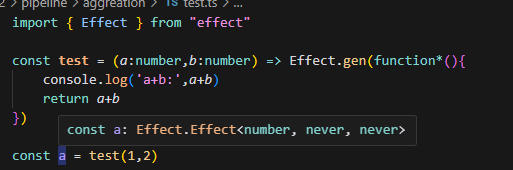

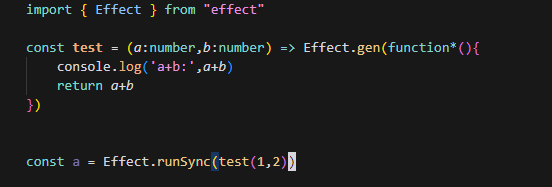
除非使用 EffectTS 的运行函数运行 Effect,它才会兑现:

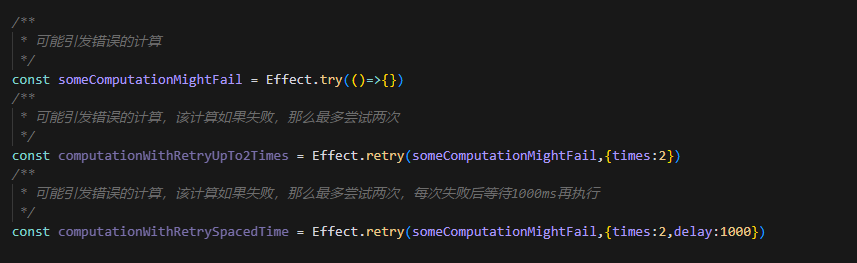
除此之外,它提供了许多方便的 API ,例如,错误重试(你不再需要恶心的多个 try-catch 了):
例如,定期执行:

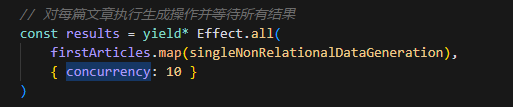
例如,并发执行:
它是非常符合我们前面提到的心智模型的:把程序看作是对数据与类型的一连串的计算。你可以通过不断创建 Effect 包装那些可能会引发错误的计算,而后将 Effect 组合起来构成你的程序。并且它能够提供丰富的类型信息,能够更好地帮我们划分程序的副作用的边界。
llm 工程
大模型是一个让人头疼的东西,因为它的输出本身就是具备不确定性的。LLM工程可能会是近二十年来最具有挑战的、让不确定性确定化的挑战了。
LLM 工程的不确定性,在我看来,可以归纳为这两点:
- 效果上的不确定性,每一次的生成都会产出不同的内容(缓存除外,在此点名 OpenAI,不过 API 调用不会出现这个问题)。
- 因为 LLM 的不确定性加剧的的工程上的不确定性:没有按预期格式输出、LLM 厂商的服务波动、账户没钱了......
效果不确定性
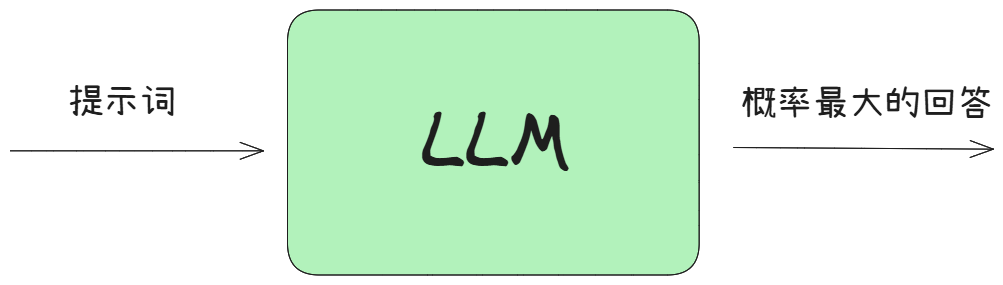
单个LLM调用效果上的不确定性可以通过提示词工程去解决,或者说,提示词工程主要做的就是确定大模型输出的效果。虽然我个人觉得 LLM 有点像一个确定下来的概率收敛的函数:传入提示词,输出它读尽了人类社会语料后,它觉得概率最大的回答。因此,我们的提示词要做的是:明晰任务,让大模型不迷惑。只有提示词明确了,大模型在才能将输出的回答收敛到正确的概率区间上。
例如,文章归类任务上,这样的提示词就是模糊的:
# 场景对文章进行相关性判断的归类,将两篇实际上讲的是一件事的文章归并为一类。
# 任务阅读提供的两篇不同文章的摘要,判断它们是否存在事实上的相关性或近似性。请从以下角度进行考虑:1.主题相关性:文章是否讨论相同的对象主题2.内容重叠:是否包含相似的关键信息或观点# 输入两篇不同文章的摘要,按以下格式提供: <article1>{article1_content}</article1> <article2>{article2_content}</article2># 输出 以该 JSON 格式返回结果: \`\`\`json { "isRelated": <是否相关,以 boolean 类型返回> } \`\`\`什么是“实际上讲的是一件事”?事是什么?事件,还是事实?
# 场景对文章进行相关性判断,将实际描述同一事件或高度相关内容的两篇文章归为同一类。
# 任务请阅读提供的两篇文章摘要,并判断它们之间是否存在事实上的相关性或近似性。在进行内容相关的判断时请明确考虑以下三个方面:1. 主题相关性:两篇文章是否讨论相同的对象、主题或事件。2. 内容重叠:两篇文章是否包含相似的关键信息、事实、观点或描述。
只有在以上两个方面任一一个符合时,才将这两篇文章归并为一类。
# 输入将以以下格式提供两篇文章的摘要:<article1>{article1_content}</article1> <article2>{article2_content}</article2>
# 输出
请以以下 JSON 格式返回结果: ```json { "isRelated": <是否相关,以 boolean 类型返回>, "reasoning": "<支持判断的简要理由,以字符串形式描述>" }这一版提示词明确了两点:
- 文章的相关性 = 描述同一事件 或 内容高度相关
- 对于内容高度相关这一方面,提供了两个指标考虑
- 确定了两个指标任一一个指标满足时,认为符合内容高度相关。
这套提示词倒说不上好,但是由于后者的提示词明确了判断逻辑,因此在输出的稳定性上会比前者好。尤其是 "只有在以上两个方面任一一个符合时,才将这两篇文章归并为一类" 这句话。
并且,对于那些指标多且不是很明晰的任务,可以考虑使用并行化,将每个指标单独拆出来让 LLM 进行读取:
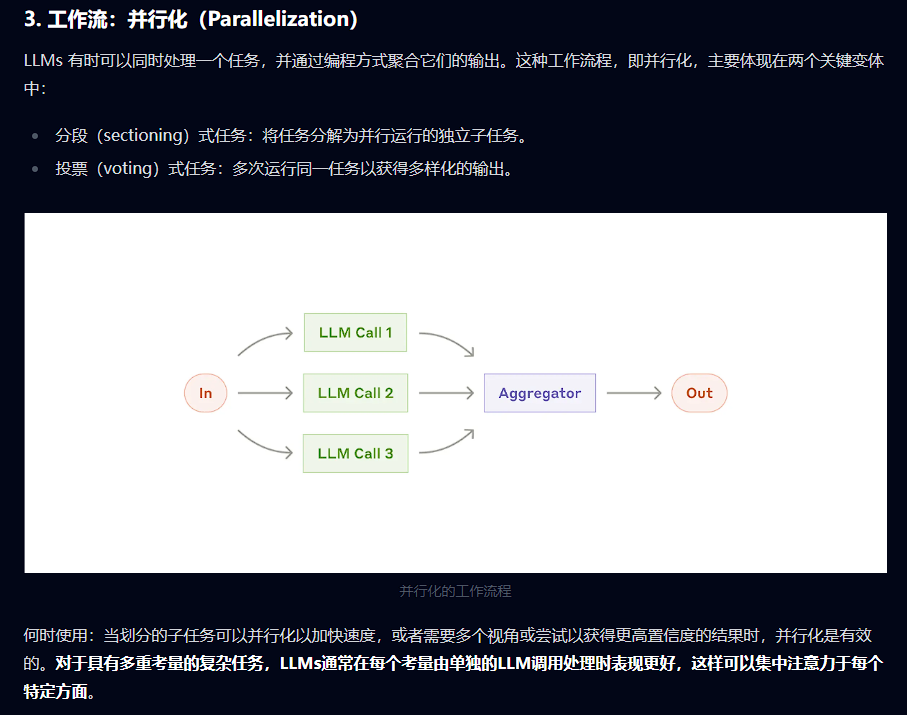

这样的优点是:
- 避免因为注意力机制造成的结果不稳定。
- 可以单独对指标进行调优。
举例:文章的评分,需要用到像是语言风格这样的模糊指标,这些指标往往需要搭配 in-context learning 才能得到比较好的效果。
如果要做并行化,为了节省成本,我们可以善用大模型厂商在去年(2024年中旬)上线的 context caching 功能:
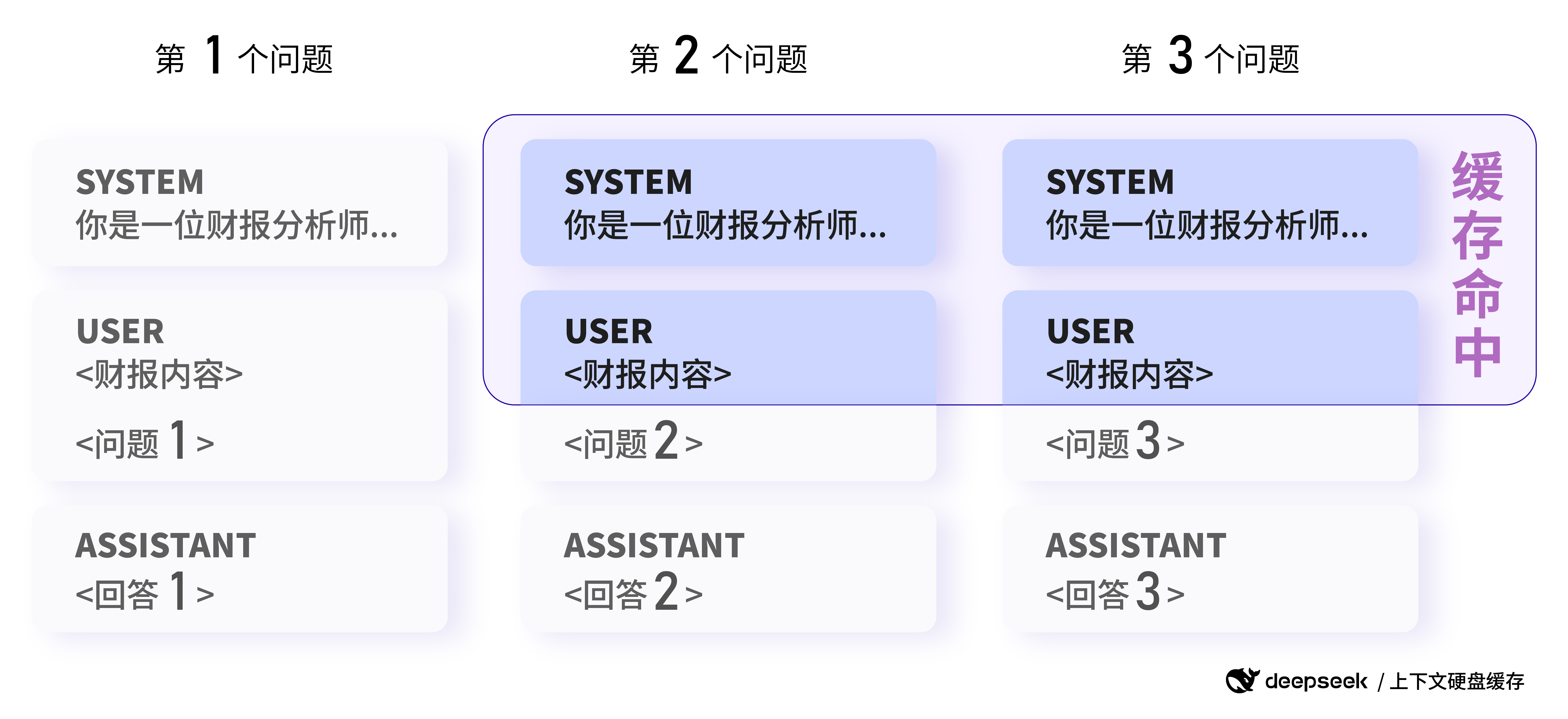
如果你想省钱,你可以尝试把数据的输入提前以保证缓存的命中(当然,效果优先,要确保效果改变不大再这么做)。
提示词工程实际上是 LLM工程 的核心,这是一个漫长的实践过程。之后我应该会在以后的内部分享里分享一下我个人的一些心得。
效果的不确定性的难点倒不在单个LLM调用上,而是在 LLM 的能力调用的不确定性上。这个比较复杂,我放在末尾细讲。
LLM工程的不确定性
LLM 工程的不确定性可以划分为这几点:
- 模型调用过程的不确定性。
- 模型返回结果的异常性。
模型调用过程的不确定性很好理解,它指的是在调用大模型时我们可能会遇到的问题,e.g.
存在以下可能的调用过程异常的边界条件:
- LLM调用中台的网络配置(Nginx转发的最长连接时延)。
- 速率限制。这个我们只在中台通过 aws 调用 Claude 的时候遇到过。
- 超过了模型上下文窗口大小。这个可通过预先计算 tokens 数量解决。
OpenAI等大模型厂商服务的不确定性。这里的不确定同样包括调用过程的不确定性(例如说我们现在是通过中台调的,嗯,过去的一年里懂得都懂)。虽然说,大部分时候厂商服务都是稳的,但是它一次的崩溃足以引发业务上的尖叫。
这种问题的解决路径通常是重试或备用路由。在备用路由上,需要我们考虑的点比较多:
- 如果是切换别的模型,不同 LLM 厂商的返回格式不同,e.g. Claude 和 OpenAI 的 Tool Use 的响应格式不同。
- 会不会对效果造成影响?
模型返回结果的异常性,指的是在调用模型的时候,偶尔会遇到模型那边发生问题/模型返回结果是不符合我们预期的。
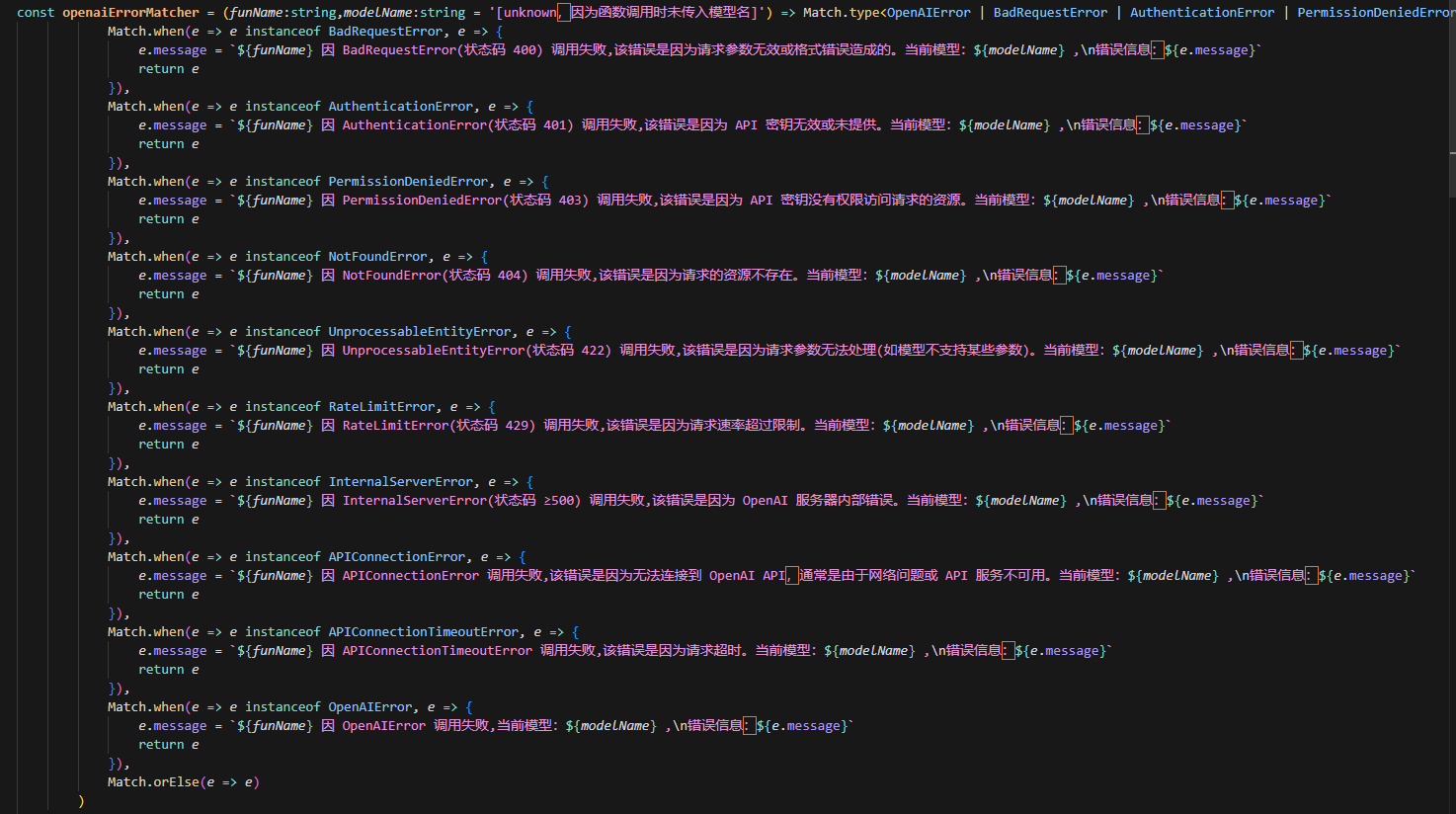
模型调用的异常可以通过先写好错误匹配的逻辑解决:
返回结果不符合我们预期这一点上,例如,它没有正确输出我们传入的例如 Id 这类的数据。解决方案很简单,我们加个校验的逻辑即可,好在借助 EffectTS ,这段代码可以非常精简:

const validation = (result:any) => result
const triangleFeatureEffect = createFeatureEffect<ArticleTriangleFeature>( articleTriangleFeatureWeight, articleContentPreShorten, { passionAttitude: 0, rigorousness: 0, interestingness: 0 } ).pipe( retryEffectIfFailedUpTo3Times, Effect.flatMap(result => validation(result)) )总结来讲,其实就是做好错误处理与校验的逻辑。
难点:模型能力的不确定性
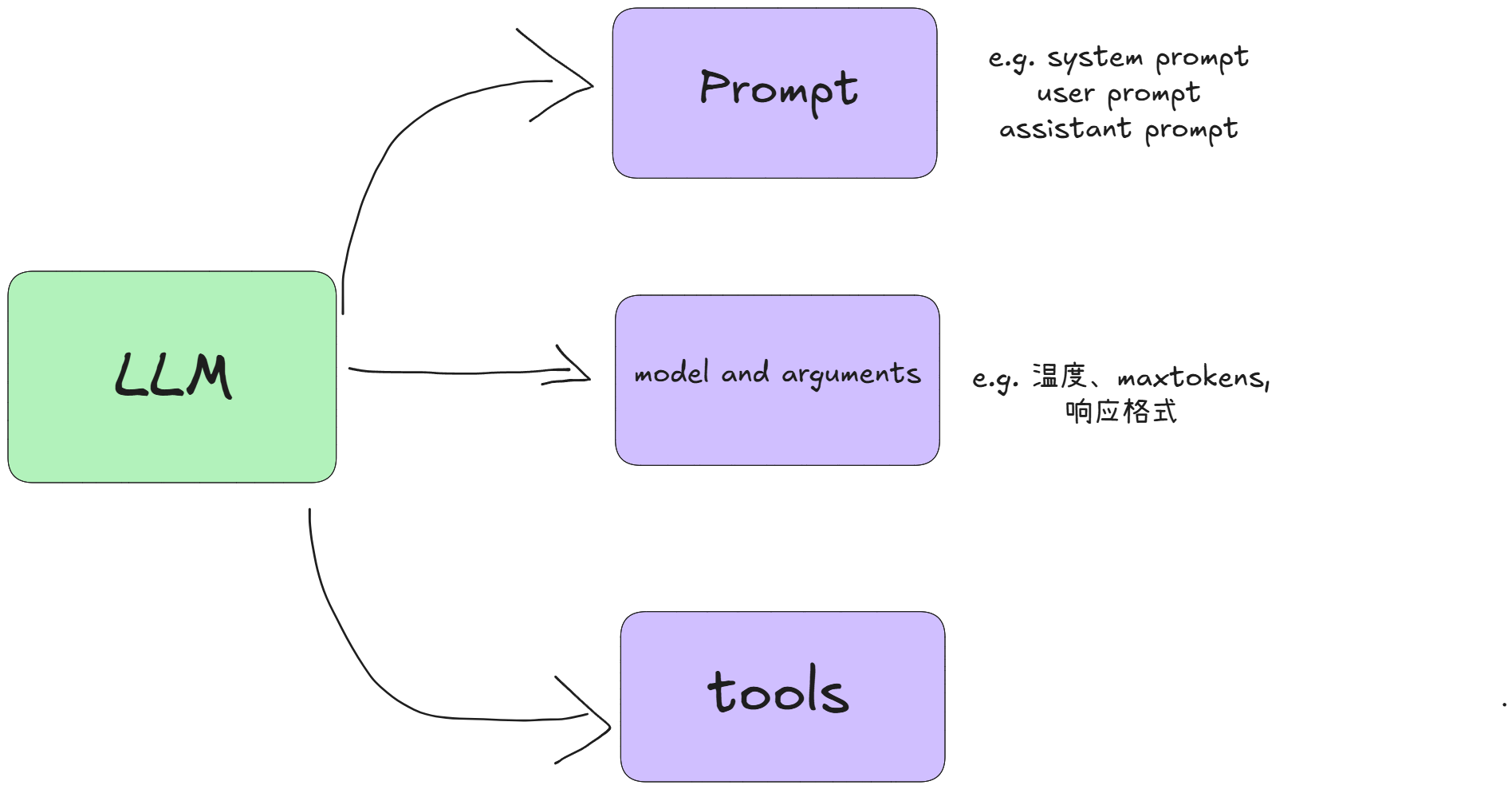
让我们先回归低层的抽象,让我们思考我们在调用 LLM 的时候,我们能够传递的东西是什么?
LLM 的调用归纳起来很简单,其实就这三者:
- 提示词,Prompt
- 选择调用的模型,以及模型的参数(模型生成的温度、响应格式)
- 以及,LLM所具备的能力,tools usage。
这里我们先不讨论多模态输出,因为多模态输出在调用上,只是变更调用的路径 API 以及模型参数罢了。
其中,最重要的是 Prompt ,Prompt 决定了 LLM 在任务上输出的效果。每一次调用 API 时,我们都是把不同角色的对话记录传入大模型,从而获得结果的。
哦对,在这里顺带提一点,我们都知道大模型有 in-context learning 的能力,所以有 few-shot 之类的提示词技巧。但是我感觉好像大家存在一个误区,那就是 few shot 必须这么写在 system prompt 里:
### 示例输入1#### TitleDynaMath: A Dynamic Visual Benchmark for Evaluating Mathematical Reasoning Robustness of Vision Language Models#### AbstractThe rapid advancements in Vision-Language Models (VLMs) have shown great\npotential in tackling mathematical reasoning tasks that involve visual context.\nUnlike humans who can reliably apply solution steps to similar problems with\nminor modifications, we found that SOTA VLMs like GPT-4o can consistently fail\nin these scenarios, revealing limitations in their mathematical reasoning\ncapabilities. In this paper, we investigate the mathematical reasoning\nrobustness in VLMs and evaluate how well these models perform under different\nvariants of the same question, such as changes in visual numerical values or\nfunction graphs. While several vision-based math benchmarks have been developed\nto assess VLMs' problem-solving capabilities, these benchmarks contain only\nstatic sets of problems and cannot easily evaluate mathematical reasoning\nrobustness. To fill this gap, we introduce DynaMath, a dynamic visual math\nbenchmark designed for in-depth assessment of VLMs. DynaMath includes 501\nhigh-quality, multi-topic seed questions, each represented as a Python program.\nThose programs are carefully designed and annotated to enable the automatic\ngeneration of a much larger set of concrete questions, including many different\ntypes of visual and textual variations. DynaMath allows us to evaluate the\ngeneralization ability of VLMs, by assessing their performance under varying\ninput conditions of a seed question. We evaluated 14 SOTA VLMs with 5,010\ngenerated concrete questions. Our results show that the worst-case model\naccuracy, defined as the percentage of correctly answered seed questions in all\n10 variants, is significantly lower than the average-case accuracy. Our\nanalysis emphasizes the need to study the robustness of VLMs' reasoning\nabilities, and DynaMath provides valuable insights to guide the development of\nmore reliable models for mathematical reasoning.### 示例输出1GPT-4o 等视觉语言模型在数学推理方面存在局限性,引入 DynaMath 动态视觉数学基准对模型进行评估有助于提升 VLM 的推理能力。但是我们要明白的是,few-shot 为的是利用大模型能够从对话的上下文中学习的能力,因此,我们可以将一轮对话作为一种 few-shot 在调用 API 时传入:
const result = await openai.chat.completions.create({ model: "gpt-4o-mini", messages: [ { role: "system", content: newPromptSystem }, { role: "user", content: "为我概括摘要:xxxxx" }, { role: "assistant", content: "GPT-4o 等视觉语言模型在数学推理方面存在局限性,引入 DynaMath 动态视觉数学基准对模型进行评估有助于提升 VLM 的推理能力....(省略500字)" }, { role: "user", content: "字数过长,你可以这样写XXXX" }, { role: "assistant", content: "GPT-4o 等视觉语言模型在数学推理方面存在局限性,引入 DynaMath 动态视觉数学基准对模型进行评估有助于提升 VLM 的推理能力。" }, {role: "user", content: "为我概括摘要:(新的摘要)"} ], })通常,我们应该在确认了 Prompt 的效果后,才会尝试对诸如温度等参数进行微调。嗯,不过至少现在我们不需要纠结这个。温度这样的参数调起来太 nerd 了。
通常,工程里,我们总是期望大模型能够给到结构化的数据,结构化输出这个特性比较操蛋,常用的JSON输出上,存在以下两种参数格式,json_object 和 json_schema:
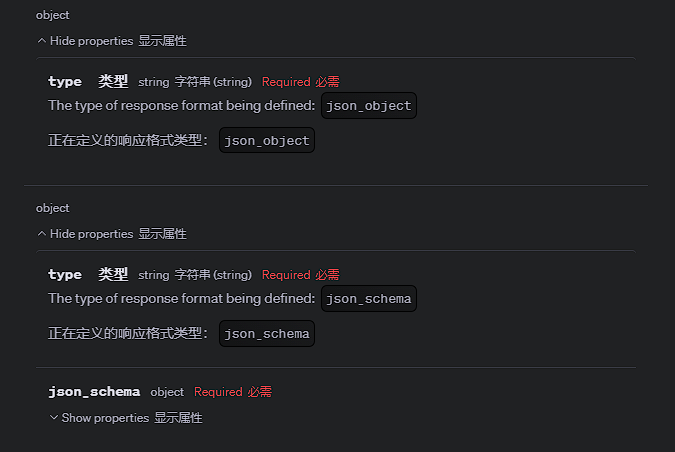
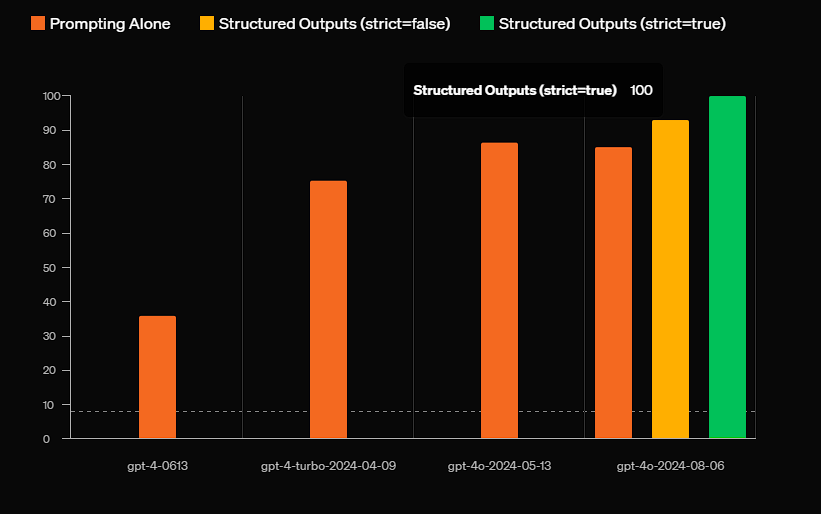
比较尴尬的一点在于,目前大部分厂商只有 OpenAI 、 Claude 这类厂商实现了 json_schema 的严格输出,国内大模型厂商的普遍支持情况停留在的是 json_object 上。
并且即使是 openai 号称使用 json_schema 能够达到 100% 的准确性的情况下,依然会出现输出的格式不符合我们要求的问题。
因此,在后续我们确定了工程效果后,我们应当做好校验与重试的逻辑:如果LLM响应不符合我们的预期格式,那么就重新发送请求进行相应的内容生成。
接下来来到我们的重头戏上,也是大模型的魅力所在:工具调用。
与其说是工具调用,我其实更喜欢把它称呼为“意图识别”。因为大模型本身不具备调用外部工具的能力,它的做法只是在用户提供了可以用到的工具以及对话上下文后,判断是否需要调用工具,而后生成工具调用的参数返回给模型的调用者:
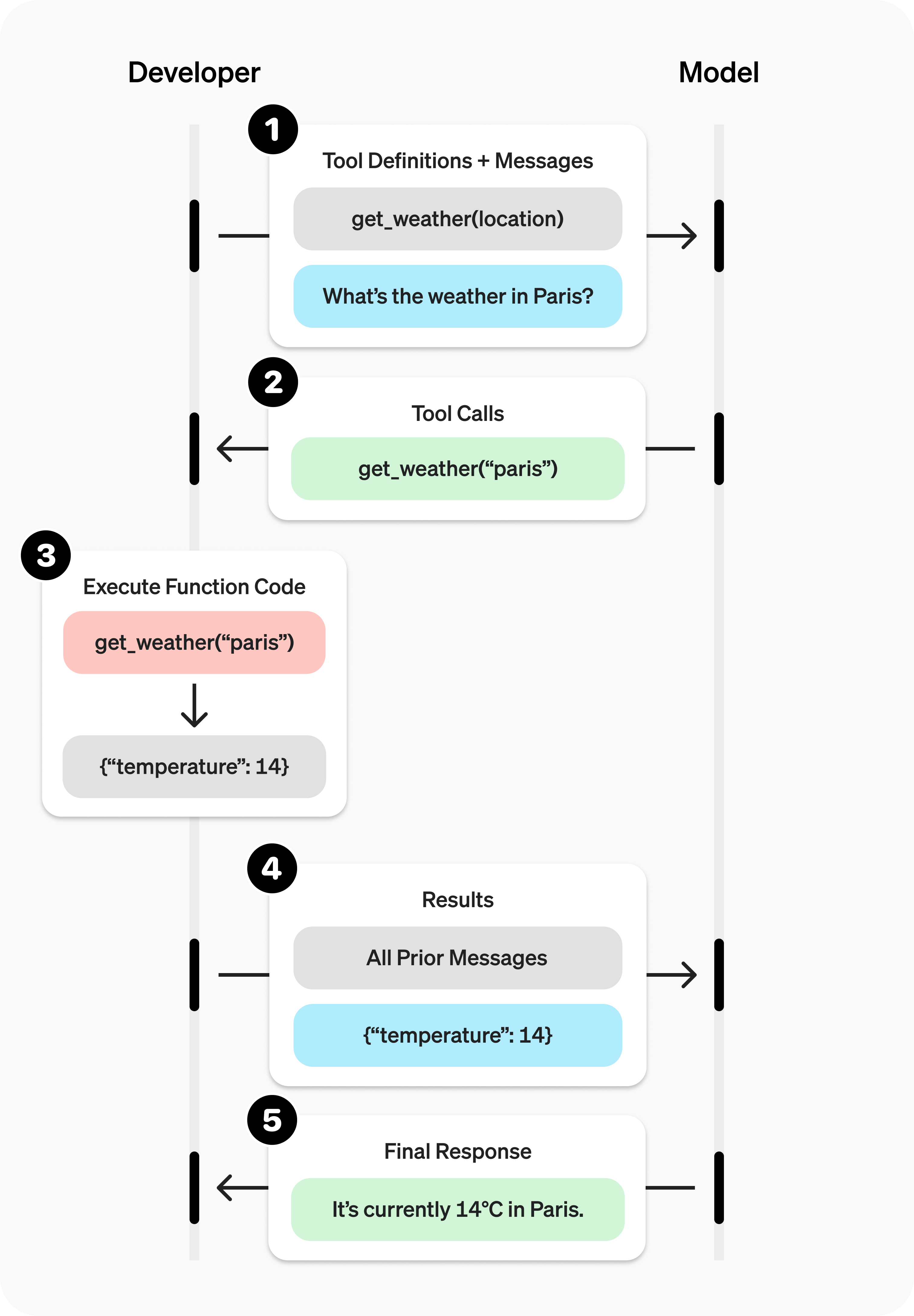
我们见到大模型厂商提供的Chatbot服务,它们之所以能够调用工具获取信息是因为你在使用的服务本身是一个封装好的工程化的产品,存在一些预制工具与预制的流程。当你和 GPT 聊天,当它判断需要从外部获取数据时,便会返回工具调用的句柄,而后它们的后端便会根据句柄去获取相应的信息,最后辅助生成回答。
也就是说,我们开发者能够控制的便是:提供我们封装好的工具信息,让大模型生成工具在开发者侧调用所需的参数后,根据参数去调用相应的工具获得结果 or 将结果返回给大模型生成更好的回答。
这一点的难点在于:大模型在多轮对话后,对于工具调用的识别率会下降。这一点估摸会是我们今年要攻克的问题。
接下来我会简单介绍一下 Anthropic 他们总结的 AI Agent 的几种构建模式。
【草稿完】
【END】