【Translation】上下文检索技术 Contextual Retrieval
"李问道个人对 Anthropic 的博文 《Introducing Contextual Retrieval》 的翻译"
本文是对 Anthropic (Claude 团队)的博文 《Introducing Contextual Retrieval》 的个人翻译,存在部分删改与个人润色。
简单来讲:上下文检索技术是一种预处理技术,它用于在对文本进行切分后,通过大模型为每个切分后的文本块添加对应上下文信息以弥补传统的做法存在的上下文丢失问题。
介绍
对于一个AI模型来说,如果要在特定的场景中发挥作用,通常需要具备相关的背景知识。例如,用于客服聊天机器人需要了解对应业务的相关知识,而法律分析机器人则需要了解大量的判决案例。
开发人员通常通过 RAG技术(Retrieval-Augmented Generation,检索增强生成技术)来增强 AI 模型的知识。简单来讲,RAG是一种通过从知识库里检索相关信息,而后附加到用户向模型输入的 prompt 里以获得更好的回复的技术。然而,传统的 RAG技术 在编码信息时会删除上下文,这往往会导致系统无法从知识库中检索到相关信息。
在本文中,我们介绍了一种可以显著提升RAG检索步骤的方法。该方法称为“上下文检索法”(contextual retrieval)。上下文检索法使用了两种子技术:
- 上下文嵌入法(Contextual Embeddings)
- 创建BM25索引法(Contextual BM25)
该方法成效显著,可以降低约 49% 的检索失败率,在与重排序(reranking,RAG常用的一种方法)结合后可降低 67% 的失败率。这代表了检索准确度的显著提升,能够让下游任务具备更好的表现。
你不需要用到这门技术的情况
有时候最简单的解决方案就是最好的。如果您的知识库大小不超过200,000个tokens(大约500页的内容),您可以直接将整个知识库作为模型的提示输入,而无需使用RAG或其他类似方法。
几周前,我们为Claude推出了 提示缓存(prompt caching) 功能,这使得直接输入整个知识库的运行速度大大加快,成本也大大降低。开发人员现在可以在API调用之间缓存常用的提示,从而将延迟降低2倍以上,成本降低90%以上(您可以通过阅读我们的 提示缓存Cookbook 了解其工作原理)。
然而,随着知识库的不断增长,你最终会需要一个扩展性更强的解决方案。这就是上下文检索发挥作用的地方。
在开始前,还要稍微讲一下 RAG 技术...
对于那些超出模型上下文窗口的大型知识库,RAG是典型的解决方案。RAG通过以下步骤对知识库进行预处理:
- 切分。将知识库(文档的“语料库”,the "corpus" of documents)切分为更小的文本片段,通常不超过几百词。
- 嵌入,或者说向量化。使用 嵌入模型(embedding model)将这些切分后的片段转换为 向量内嵌(vector embeddings),这些 向量内嵌 是一种对语义的编码。
- 存储。将这些向量内嵌存储在一个允许 基于语义相似性 进行搜索的向量数据库中。
在运行时,当用户向模型输入查询时,向量数据库将根据语义相似性来查询最相关的片段。然后,将最相关的片段添加到发送给生成模型的提示中。
虽然嵌入式模型擅长捕捉语义关系,但它们可能会错过关键的精确匹配。幸运的是,有一种更古老的技术可以在这种情况下提供帮助,那便是建立 BM25 的索引法。BM25(Best Matching 25)是一种排名函数,它使用词法匹配来查找精确的单词或短语匹配。对于包含唯一标识符或技术术语的查询,它非常有效。
BM25 是建立在 TF-IDF(Term Frequency-Inverse Document Frequency,词频-逆文档词频,一种用于信息检索与数据挖掘的加权技术)概念之上的。TF-IDF 用于衡量一个词对于文档集合的重要性。BM25 对 TF-IDF 进行了改进,考虑了文档长度,并对词频应用了饱和函数,这有助于防止常见词主导结果。
BM25可以在语义嵌入模型无法成功的情况下取得成功:假设用户在一个提供技术支持的数据库中搜索“Error code TS-999”。使用语义嵌入模型可能会找到关于错误代码的一般内容,但可能会错过“TS-999”的精确匹配。而BM25会寻找这个特定的文本字符串(“TS-999”)来识别相关的文档。
译注:因为向量搜素是一种在阈值范围内的模糊搜索,因此可能会搜出一堆 Error Code xxxx 的内容,而缺少精准搜索。
创建 BM25 索引法和上下文嵌入法的区别是两者的编码方式不同。
RAG技术通过以下步骤将嵌入技术和BM25技术结合起来,从而更准确地检索出最适用的片段:
- 切分。将知识库(文档的“语料库”,the "corpus" of documents)切分为更小的文本片段,通常不超过几百词。
- TF-IDF编码(即建立BM25算法可用的索引)与嵌入。在传统 RAG 的解决方案上,添加了为各个片段创建 TF-IDF 编码的步骤。
- BM25搜索。使用BM25算法根据精确匹配来查找匹配度高的片段。
- 使用嵌入技术根据语义相似性找出最优片段。
- 将步骤(3)和(4)得到的结果进行合并和去重,使用 排名融合(ranking fusion,将两种排名的结果进行汇合) 技术。
- 将排名中前K个片段添加到提示中以生成响应。
通过结合BM25和嵌入模型,传统的RAG系统可以提供更全面和准确的结果,在术语的精确匹配与更广泛的语义理解之间实现平衡。
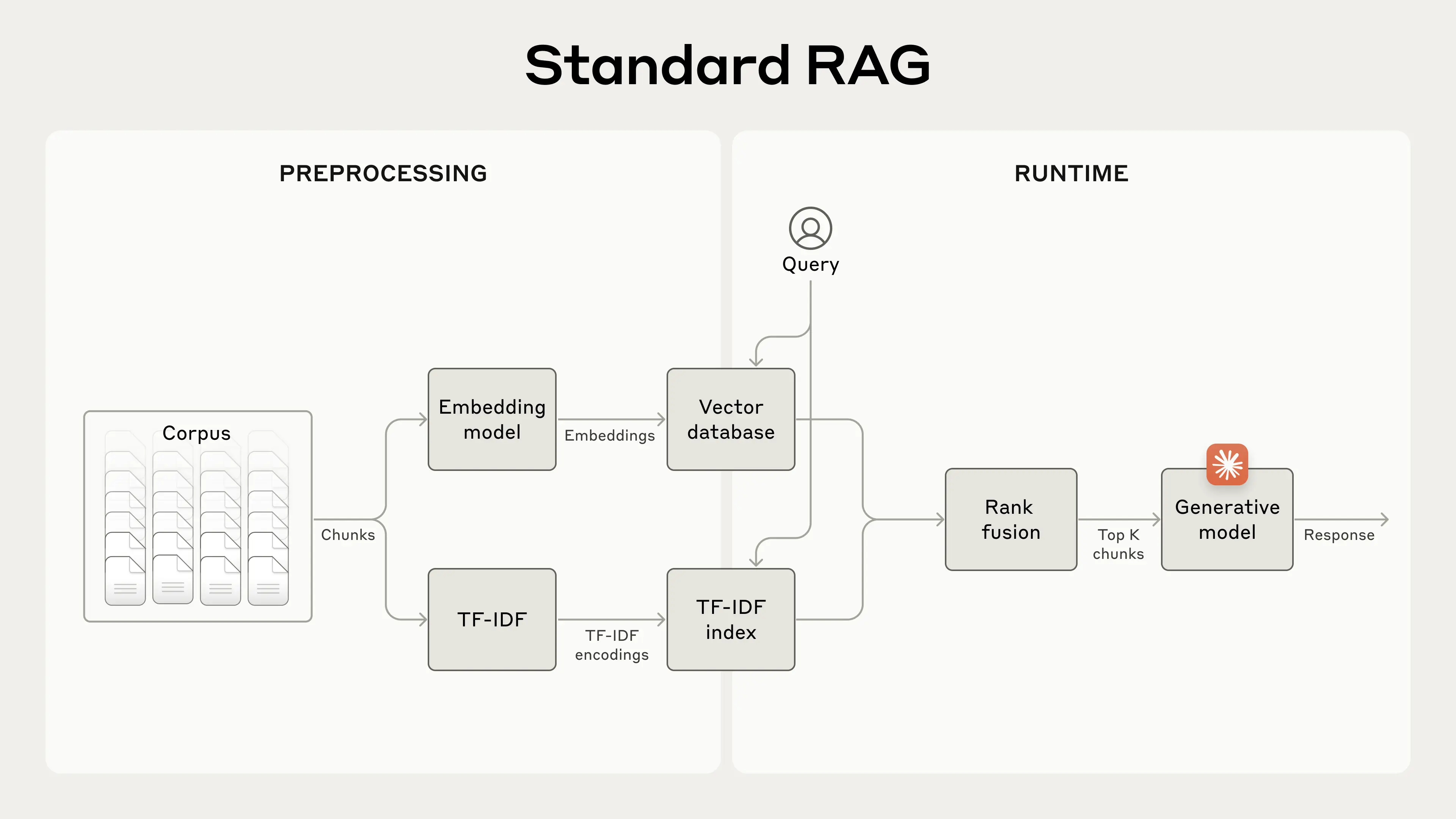
这种方法可以让您以较低的成本扩展到庞大的知识库,其规模远远超出单个提示所能容纳的范围。但是,这些传统的RAG系统有一个显著的局限性:它们常常会破坏上下文。
传统RAG方法中的上下文难题
在传统的RAG系统中,文档通常会被分割成更小的片段以提高检索效率。虽然这种方法对于许多应用来说效果很好,但如果每个片段缺乏足够的上下文信息,就会引发问题。
例如,假设你的知识库中包含了一系列财务信息,例如美国证券交易委员会(SEC)的文件,然后你收到了如下问题:“ACME公司在2023年第二季度的营收增长率是多少?”
相关的片段可能包含这样的文字:“该公司上一季度的营收增长了3%。” 然而,仅凭这一片段本身无法确定它所指的公司或相关的时间段,这使得很难获取正确的信息或有效地使用这些信息。
解决该问题的上下文检索法
上下文检索法 通过在 创造文本语义内容的向量嵌入(contextual embeddings) 与 创建BM25 索引(contextual BM25) 之前为每个片段添加该片段的解释性上下文(explanatory context)来解决这个问题。
例如,让我们回到上边的 SEC 文件的索引例子上,这是片段在切分后会被如何转换的示例:
# 原始文本块# “公司营收较上季度增长了 3%”original_chunk = "The company's revenue grew by 3% over the previous quarter."
# 经过上下文检索后补充了解释性上下文的文本块。“。”前的内容为解释性上下文# “这段内容来自ACME公司关于2023年第二季度业绩的SEC文件;上一季度的收入为3.14亿美元。公司的收入比上一季度增长了3%”contextualized_chunk = "This chunk is from an SEC filing on ACME corp's performance in Q2 2023; the previous quarter's revenue was $314 million. The company's revenue grew by 3% over the previous quarter."值得注意的是,过去也曾提出过其他利用上下文来改进检索的方法。这些方法包括:在片段中添加通用文档摘要(我们对它做了实验,只能说收益并不显著)、假设性文档嵌入(HyDE)以及 基于摘要的索引法(我们进行了评估,它们的性能并不高)。这些方法与本文中提出的方法存在不同。
如何实施上下文检索法
当然,手动为知识库中的数千甚至数百万个片段添加注释将是一项非常繁重的工作。为了实现上下文检索,我们转向了Claude。我们编写了一个prompt,让模型为每个片段提供简洁的、针对特定片段的上下文,以使用整个文档的上下文来解释该片段。我们使用以下用于 Claude 3 Haiku 模型的 prompt 为每个片段生成解释性的上下文:
# 英文原本的 Prompt:<document>{{WHOLE_DOCUMENT}}</document>Here is the chunk we want to situate within the whole document<chunk>{{CHUNK_CONTENT}}</chunk>Please give a short succinct context to situate this chunk within the overall document for the purposes of improving search retrieval of the chunk. Answer only with the succinct context and nothing else.
# 中文翻译# document 标记用于标识原文档的内容的存放位置
<document>{{WHOLE_DOCUMENT}}</document>以下是我们希望在整个文件中定位的部分,以<chunk>标识:<chunk>{{CHUNK_CONTENT}}</chunk>请给出简短且精炼的上下文,以便在整个文件中更好地检索此部分内容。仅回答简短的上下文,除此之外不回答任何内容。它生成的解释性上下文文本通常为50-100个词,在创建向量嵌入和创建BM25索引之前,会将其添加到片段之前。
这张图诠释了实际的数据预处理流程:
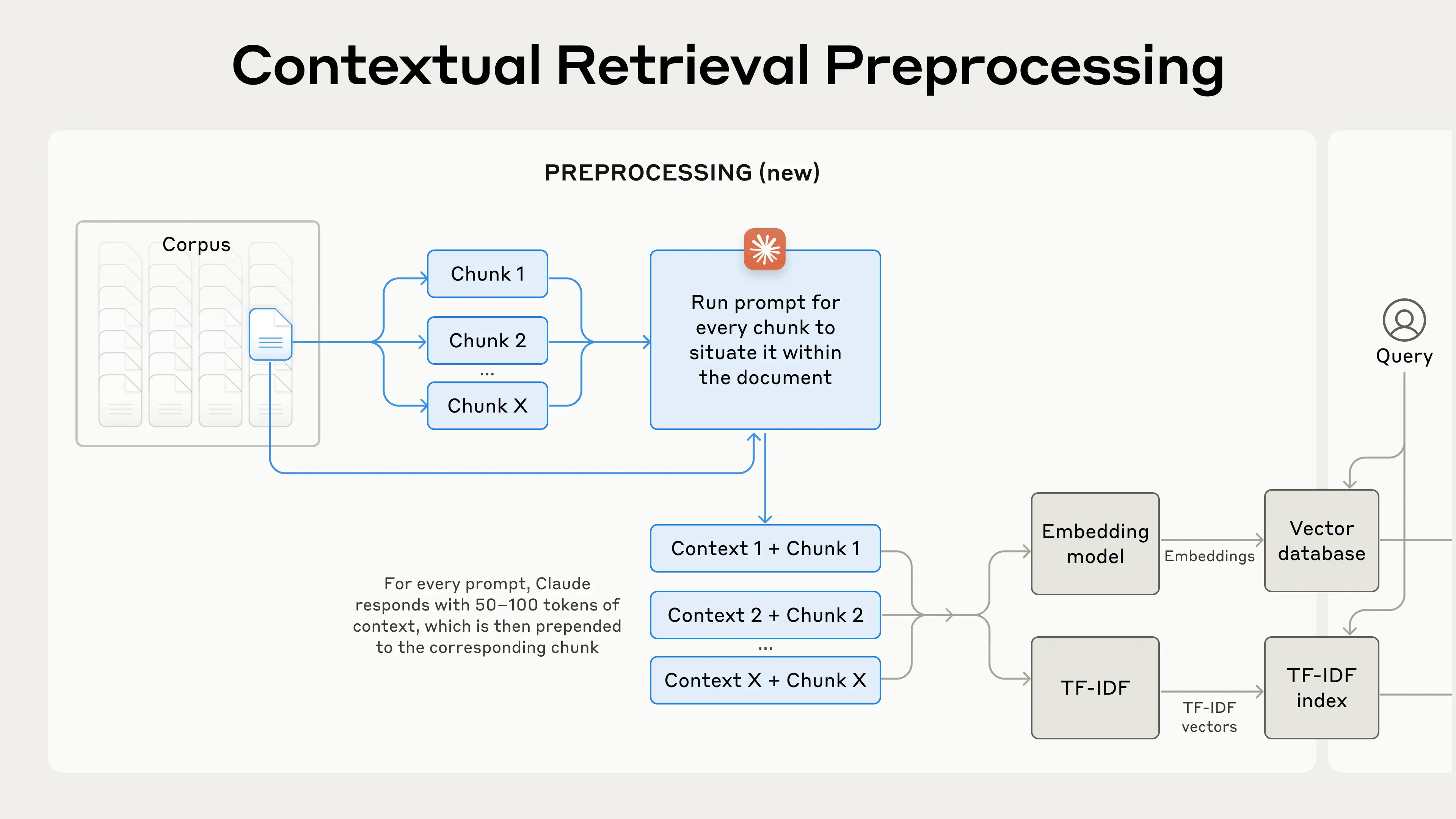
如果你对使用上下文检索技术感兴趣,你可以通过 Claude 团队的 Cookbook 进行尝试。
上下文检索法性能与成果
我们在多个知识领域(代码库、小说、ArXiv论文、科学论文)、嵌入模型、检索策略和评估指标方面进行了实验。在 附录II 中,我们列举了一些不同领域的问题和答案的例子。
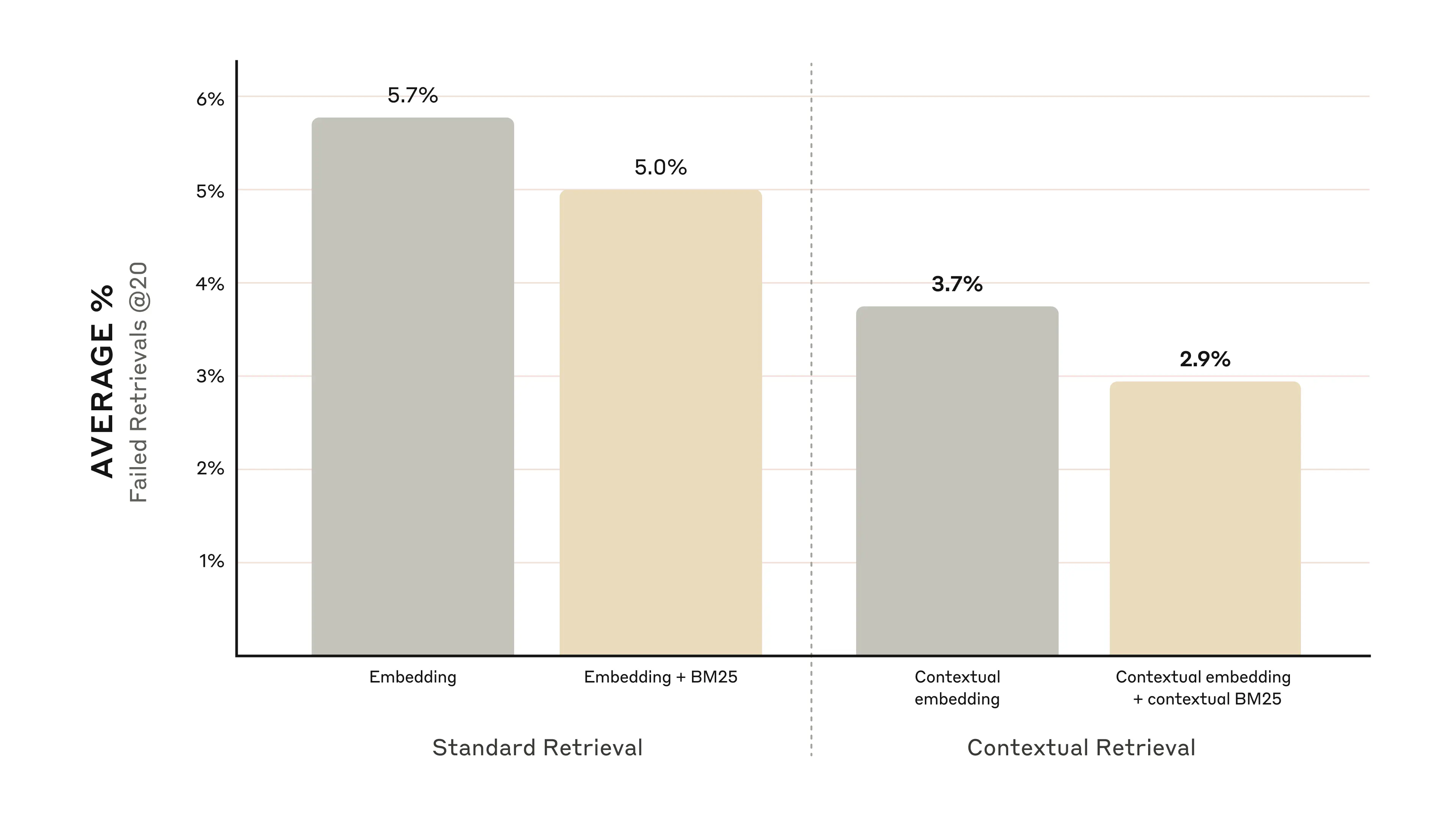
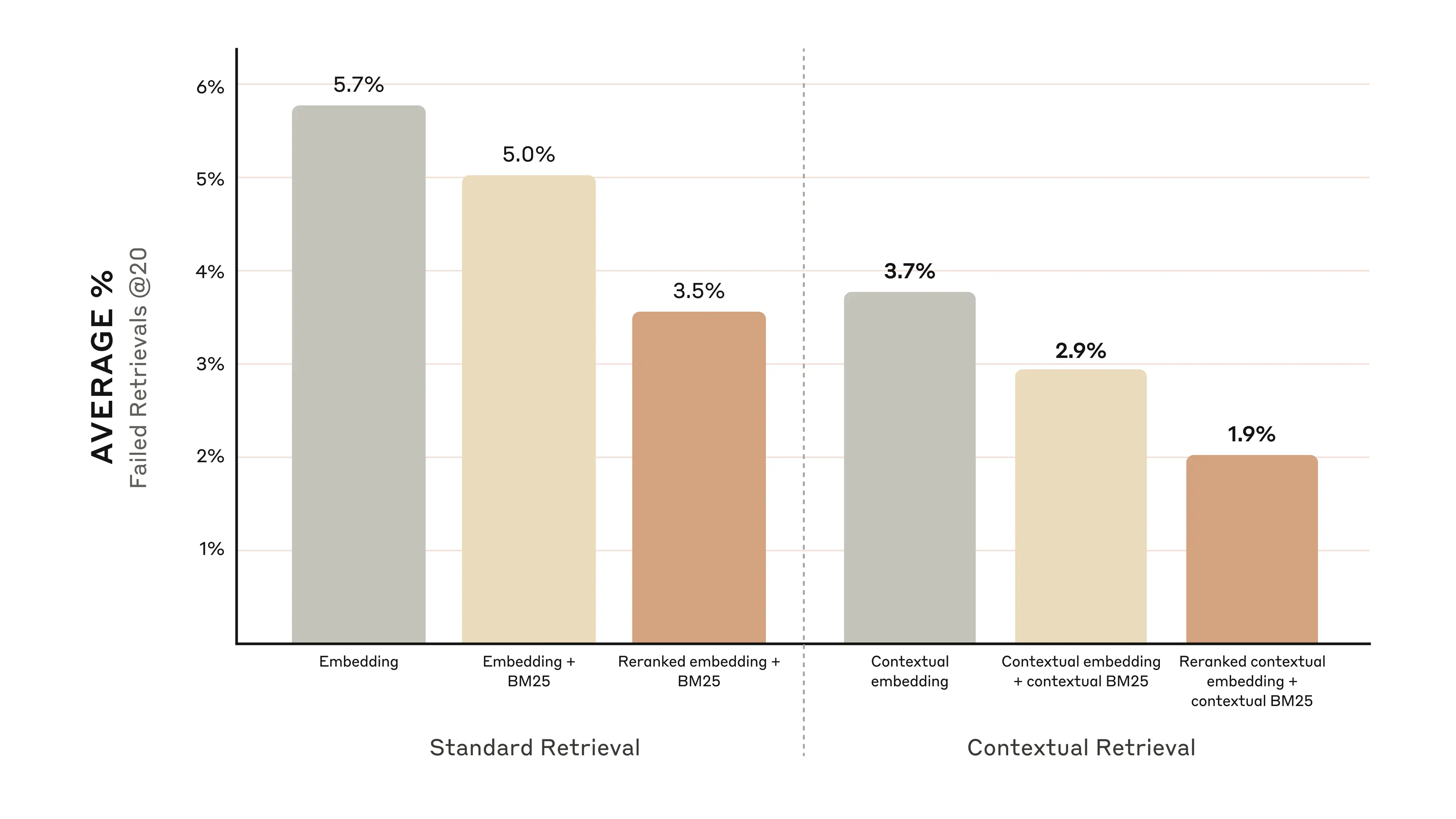
下面的图表显示了所有知识领域的平均表现,其中使用了表现最佳的嵌入配置(Gemini Text 004),并检索了前20个片段。我们使用 1 - 前20个检索结果中的相关文档数/所有相关文档数 作为评估指标,该指标衡量在前20个片段中未能检索到相关文档的比例。您可以在附录中查看完整的结果。
在我们评估的所有的 嵌入源组合(embedding-source combination)中,上下文化( contextualizing,即应用了上下文检索技术)都提高了性能。
上下文检索法的性能提升
我们的实验表明:
- 上下文嵌入将前20个片段的检索失败率降低了35%(从5.7%降至3.7%)。
- 结合上下文嵌入和上下文BM25算法将前20个片段的检索失败率降低了49%(从5.7%降至2.9%)。
实施上下文检索法时的考虑因素
在实施上下文检索法时,需要考虑以下几点:
- 分块时的边界区分(chunk boundaries):考虑如何将文档分割成不同的文本块。分块大小、分块边界和分块重叠的选择都会影响检索性能1。
- 嵌入模型(embedding model):虽然上下文检索法在所有我们测试的嵌入模型上都提高了性能,但有些模型可能比其他模型受益更多。我们发现 Gemini 和 Voyage 的嵌入效果特别显著。
- 定制上下文提示(custom contextualizer prompts):虽然我们提供的通用提示效果不错,但您可能可以通过针对特定领域或使用场景的提示获得更好的结果(例如,包括一个仅在其他知识库文档中定义的关键术语词典)。
- 分块的数量(number of chunks):将更多的分块添加到上下文窗口中可以增加包含相关信息的可能性。然而,对于模型来说,过多的信息可能会分散注意力,因此存在一定的限制。我们尝试了5、10和20个分块,发现使用20个分块是最有效的选择(参见附录中的比较),但值得针对您的具体使用情况进行实验。
- 始终运行评估(always run evals):通过将上下文化片段传递给它,并区分上下文和片段,可以改进模型的响应生成。
使用重排序进一步提升性能
在最后一步,我们可以将上下文检索与另一种技术结合起来,以进一步提高性能。在传统的RAG系统中,AI系统会搜索其知识库以查找潜在的相关信息片段。对于大型知识库,这种初始检索通常会返回大量片段——有时多达数百个——其相关性和重要性各不相同。
重排序是一种常用的过滤技术,旨在确保只有最相关的片段传递给模型。重排序可以提供更好的响应,减少成本和延迟,因为模型处理的信息更少。其关键步骤如下:
- 进行初步检索以获取前150个最有可能相关的片段(我们使用了前150个)。
- 将前N个片段以及用户的查询传递给重排序模型。
- 使用重排序模型,根据每个片段与提示的相关性和重要性为其打分,然后选择前K个片段(我们使用了前20个)。
- 将前K个片段作为上下文传递给模型,以生成最终结果。
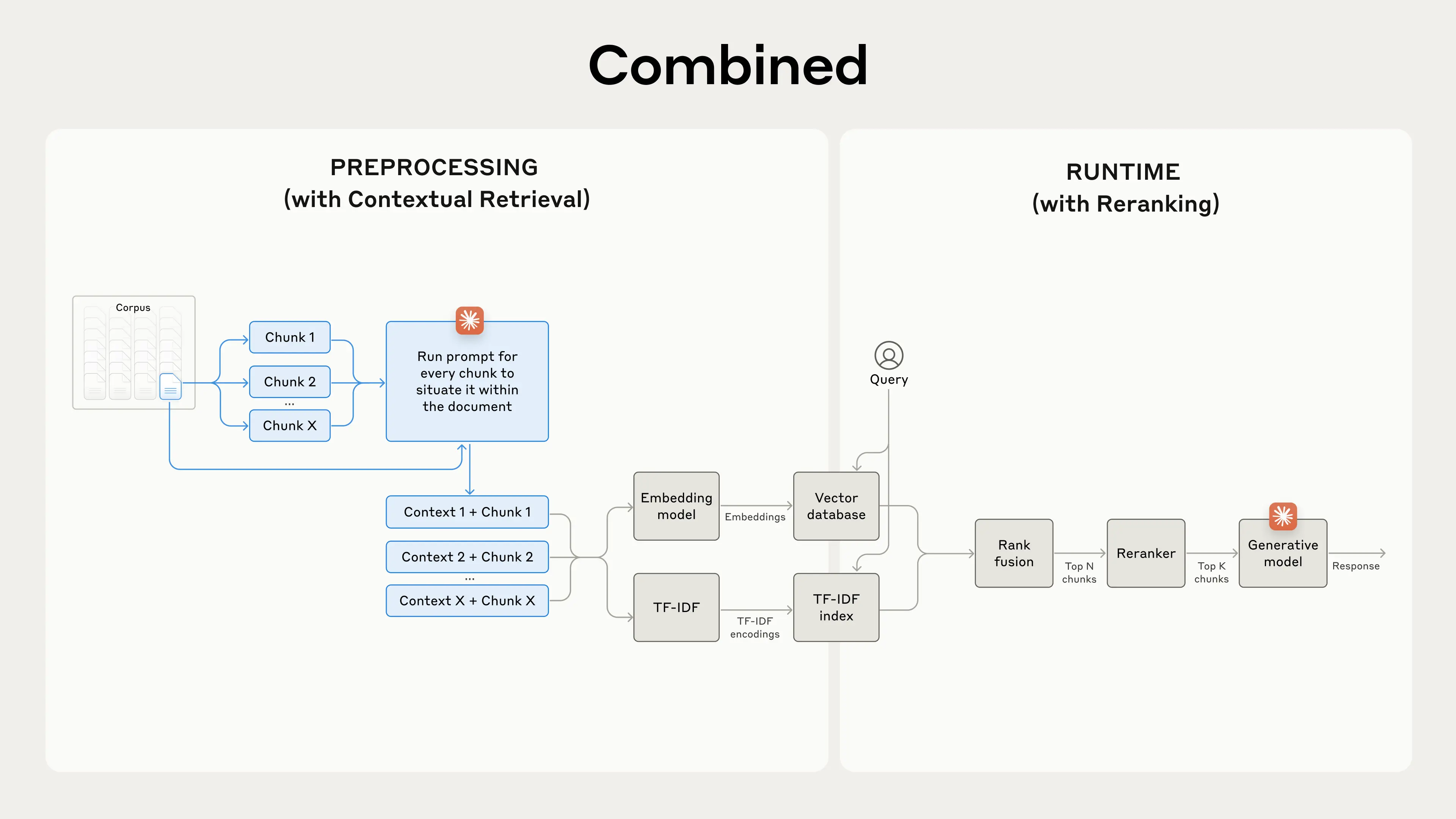
使用了重排序后的性能提升
市面上有多种重排序模型。我们对 Cohere排序器 进行了测试。Voyage 也提供了一个排序器,但由于时间原因我们未能对其进行测试。我们的实验表明:在各种领域中,添加重排序步骤进一步优化了检索效果。
具体来说,我们发现排序后的 “上下文嵌入” 和 “创建BM25索引” 将前20个片段的检索失败率降低了67%(从5.7%降至1.9%)。
成本和延迟的考虑因素
重排序的一个重要考虑因素是其对延迟和成本的影响,尤其是在对大量片段进行重排序时。因为重排序在运行时增加了一个步骤,所以即通过并行使用重排序器处理所有片段,也必然会增加一定的延迟。在提高性能与降低延迟和成本之间存在固有的权衡。我们建议针对特定使用场景进行实验,以找到合适的平衡点。
结论
我们进行了大量的测试,比较了上述所有技术的不同组合(嵌入模型、使用BM25、使用上下文检索、使用重排序器以及获取的前K结果总数),这些技术在各种不同类型的数据集上都得到了应用。以下是我们的发现:
- 结合使用 向量嵌入 + BM25索引 比 单独使用向量嵌入 进行检索的效果更好。
- 使用Voyage和Gemini的嵌入模型获得的效果更好。
- 将前20个片段传递给模型比只传递前10个或前5个片段更有效。
- 为片段添加上下文可以大大提高检索准确性。
- 有重排序总比没有排序要好。
- 这些好处能够叠加。为了最大化性能提升,我们可以将上下文嵌入(来自Voyage或Gemini)与上下文BM25结合起来,再加上重新排序步骤,并将20个片段添加到提示中。
附录I
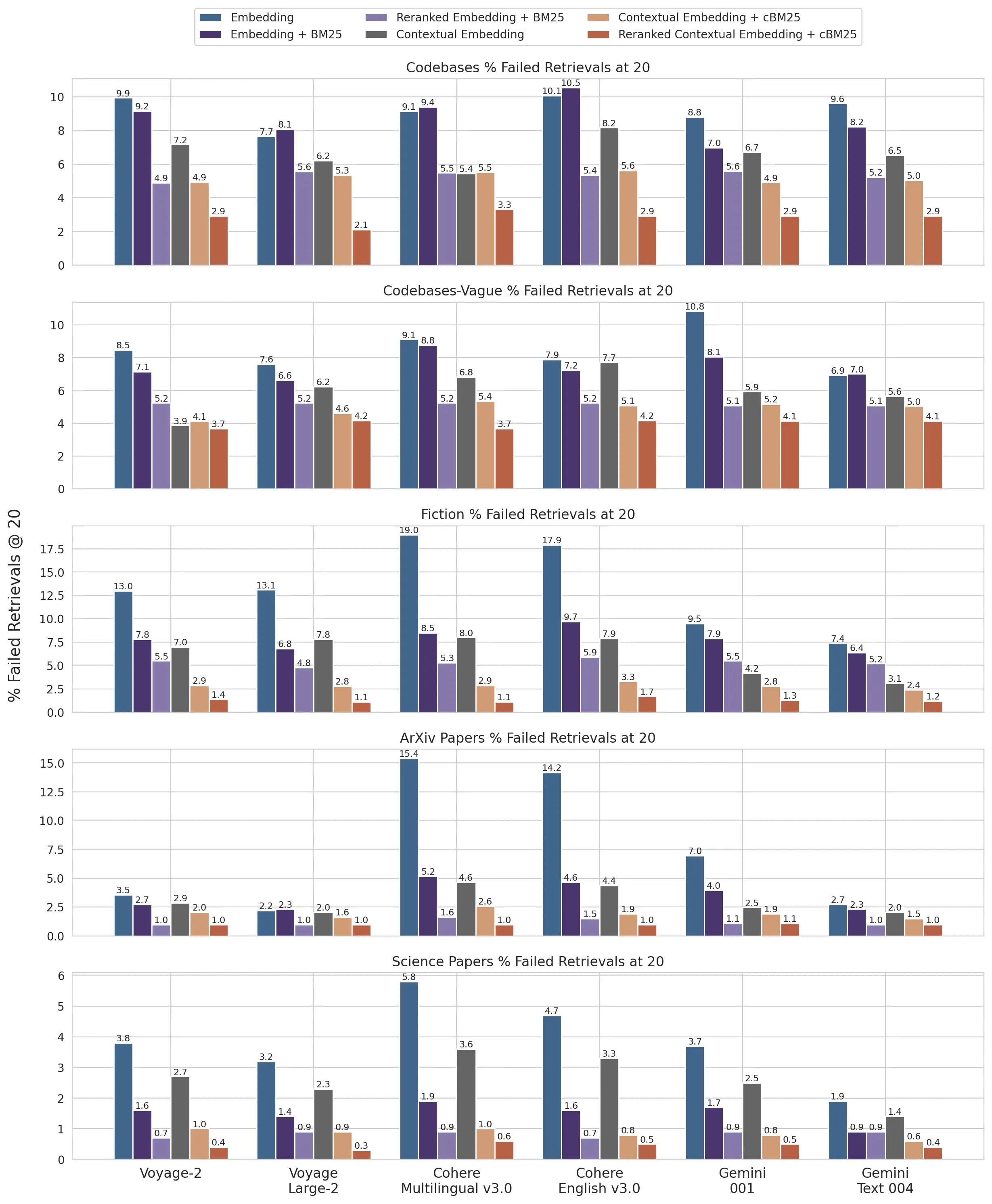
以下是对不同数据集、嵌入提供商、是否使用BM25与嵌入结合、是否使用上下文检索以及是否使用重排序进行的分析,以评估在使用前20个片段下的检索的表现。
附录II
附录II 提供了在使用前 10 与 前5个片段的检索情况以及每个数据集的示例问题和答案。
Footnotes
【END】