【WIP】个人梳理的 LLM 阅读材料和文献 - 2025
"个人梳理的 LLM 阅读材料和文献,也许它能够帮助到你?"
[updated] 最后更新于 2025-07-01
这一篇是我个人梳理的感觉具有阅读价值的 LLm 领域的阅读材料和文件,还在不断更新中。 如果你是抱有理解基本概念与学习的想法来找阅读材料,请不要看在文章尾部的 MARKS 相关文档
Prompt Engineering
Weng, Lilian. (Mar 2023). Prompt Engineering.
- 【✨重点推荐,基本把Prompt Engineering 梳理完了,感觉 prompt 没什么好说的,读完这篇文章就完事了】翁荔的博客:Weng, Lilian. (Mar 2023). Prompt Engineering. Lil’Log. https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/
LLM 测试
Claude,如何开发 LLM 的测试用例
-
【Claude】如何开发LLM的测试用例:https://docs.anthropic.com/zh-CN/docs/build-with-claude/develop-tests
所谓测试,本质是 build evals ,构建评估。
Anthropic Cookbook
- 【Anthropic 的 Building Evals Cookbook 示例】https://github.com/anthropics/anthropic-cookbook/blob/main/misc/building%5Fevals.ipynb
Agent
Weng, Lilian. (Jun 2023). “LLM-powered Autonomous Agents”
-
【✨重点推荐】翁荔的博客:Weng, Lilian. (Jun 2023). “LLM-powered Autonomous Agents”. Lil’Log. https://lilianweng.github.io/posts/2023-06-23-agent/
We can roughly consider the following mappings: 我们可以大致考虑以下映射:
- Sensory memory as learning embedding representations for raw inputs, including text, image or other modalities; 感官记忆作为学习嵌入表示,适用于包括文本、图像或其他模态的原始输入;
- Short-term memory as in-context learning. It is short and finite, as it is restricted by the finite context window length of Transformer. 短期记忆即上下文学习。它短暂且有限,受限于 Transformer 的有限上下文窗口长度。
- Long-term memory as the external vector store that the agent can attend to at query time, accessible via fast retrieval. 长期记忆作为外部向量存储,代理在查询时可通过快速检索访问。
Anthropic 总结的代理系统的模式
- 【Anthropic 总结的代理系统的模式】https://leewendao.otterstack.cn/writings/translations/building-effective-agents-zh
其中,LangChain 团队在他们的 LangGraph 文档中给出了这些模式的具体实现:https://langchain-ai.github.io/langgraphjs/tutorials/workflows/
Agent 是一个 loop
- 【philz.dev 的博客】https://philz.dev/blog/agent-loop/。我非常喜欢他在开头放出的几行代码,非常简洁且具备概括性:
def loop(llm): msg = user_input() while True: output, tool_calls = llm(msg) print("Agent: ", output) if tool_calls: msg = [ handle_tool_call(tc) for tc in tool_calls ] else: msg = user_input()- 【simon willisons 的博客】https://simonwillison.net/search/?q=agent+loop。西蒙·威尔逊的博客有很多关于 AI 的比较深入且富有见解的讨论。建议多多阅读他的内容。
12-factors-agents:关于构建 agent 的 12 个要素
- 【12-factors-agents】https://github.com/humanlayer/12-factor-agents/blob/main/content/factor-01-natural-language-to-tool-calls.md。言简意赅的好项目。
RAG
Retrieval-Augmented Generation for Large Language Models: A Survey
- 【✨关于 RAG 的综述论文,读完这篇你就大概懂了】https://arxiv.org/abs/2312.10997
Anthropic,Contextual-Retrieval
- 【✨Anthropic 的上下文检索介绍】这一篇讲述了如何增强 RAG 的检索性能 https://www.anthropic.com/news/contextual-retrieval,我的个人翻译:https://leewendao.otterstack.cn/writings/translations/introducing-contextual-retrieval-anthropic
结构化输出
LLM 如今依然是一个蛮荒生长的领域。关于如何让大模型能够按照我们期望的格式输出至今没有一个统一的、最优的、可以说是在绝大多数应用场景下99%可靠的方案。
我比较喜欢 BAML 团队的这篇博文:提示词 vs JSON Mode vs Function Calling vs 受限生成 vs 模式对齐解析(SAP),总结来讲,为了结构化输出相应的内容,我们能做的东西有:
- 纯粹通过提示词工程+JSON Schema实现(最差的方法)
- 借助受限生成(Constrained Generation),然而这个方法只适用于提供语法解析接口的开源模型,对主流的LLM并不友好。比较大模型LLM会存在一个底层调用的硬编码模板。
- 借助模型层面的工具/函数调用(function calling/tool use) API。这也许是当下最主流的做法,但它不适用于所有模型,要看模型厂商或者说模型本身是否支持。这一点也可以扩展到 OpenAI 的结构化输出API(structure output)上,你懂的,我们还没有一个统一的方案。LLM还是一个新兴行业,我们都在荒蛮前行中。
- 解析大模型产出的结果失败时则进行重试。这是 LangChain 等主流框架的方案。
- 生成时不直接输出JSON而是输出代码的的AST,借助相应语言的AST解析器解析得到数据。非常有趣的方向,因为模型输出的代码在长度上较小,更易于 LLM 理解。但它依然跟 LLM 自身的输出能力存在关系,且依赖于语法解析器。
- BAML 团队的模式对齐解析技术(SAP)。它的思路和我之前的想法如出一辙: 与其依赖模型严格理解我们期望的格式,不如编写一个解析器,它能宽容地读取输出文本,并运用对原始模式的理解进行纠错处理。它也是在得到结果的解析上做文章,我觉得这个比较靠谱。
除此之外,这一块我还比较喜欢他们的 你的提示词在使用比你预期多出4倍的token量 。这篇博文给出了他们对于为什么不应该在提示词中使用
JSON Schema定义内容的理解(对于 OpenAI 这类存在通过 JSON Schema 实现结构化输出API厂商,我觉得你传入 JSON Schema 本身也会在模型调用时硬编码对应的定义进入提示词空间中,只是他们微调做得太好了)。说服我的核心观点是:LLM底层的 Transformer 架构决定了,对于 JSON Schema 这种存在大量冗余字符的格式内容来说,相关标记之间的平均距离过长会带来注意力理解上的困难,从而造成生成效果不佳。
- 清华团队的论文,提供了关于模型结构化输出的测试集:Learning to Generate Structured Output with Schema Reinforcement Learning。
一些通用结论,有实践意义
推理模型并非总能表达它的思考过程
- 【Reasoning Models Don't Always Say What They Think】https://arxiv.org/abs/2505.05410
总结便是:对于未在模型训练时对齐的范式的任务,推理模型相应的思考可能并不靠谱。 这个比例大概在 20% 。 对于不正确的推理,往往相应的推理思考过程更加冗长且复杂,往往包含针对事实的不正确答案。即错误推理具备这样的特征。
大模型知道自身会在什么时候感到困惑
- 【大模型知道自身会在什么时候感到困惑】https://arxiv.org/abs/2410.02707
大模型是自回归的,意味着初始步骤的错误会导致错误的累积
- 【传统自回归模型 autoregressive langauage model】https://deepgenerativemodels.github.io/notes/autoregressive/
自回归 = self + regressive,上一步的输出会是下一步的输入,而后进行预测。 由于训练 LLM 的方式是自回归的,所有输入是真实值,因此 LLM 会信任自己的输入。这是 LLM 的根本缺陷之一。
LLM并不会推理,添加某些子句会导致性能极大下降
- 【大模型并不在做推理,仅仅只是复制了在训练数据中观察到的推理步骤,添加一个似乎与问题相关的子句会导致所有最先进的模型的性能显著下降(高达 65%)】https://arxiv.org/abs/2410.05229
测试时间缩放
- 【test-time scaling,测试时间缩放】对于推理模而言,给LLM更多的思考时间,它能够得到更好的结果。
嵌入的使用技巧
总结来讲:
- 目前大多数 LLM 厂商会做嵌入的归一化,因此,最好使用点积。
- 将嵌入视为球体
- 使用逻辑回归(logistic regression)
一些有理论意义的文章
- 【大模型安全相关:基于对数概率信息的自适应越狱攻击/预填充攻击/转移攻击】https://arxiv.org/abs/2404.02151
对于 【基于对数概率信息的自适应越狱攻击】,简单来讲就是由于 LLM 底层是基于概率去预测下个 token 的,因此用户可以通过设计一个对抗性提示模板,然后通过随机搜索或其他优化策略,在后缀中寻找能够使目标 token 的对数概率最大化的内容,从而诱导模型输出越过其安全对齐限制的内容。
【预填充攻击】,模型如果不提供对数概率信息,那么可以在 prompt 中特地添加那些模型认为不安全的信息(e.g. 特朗普白宫黑幕,假设这一段内容会触发审查,那么便故意在 prompt 中添加“特朗普白宫黑幕”的关键词,例如对于推理模型可以通过
<think>标签进行攻击)越过限制。【转移攻击】当你构建了一个越狱的 prompt 后,可以试着将它应用到其他模型上进行攻击,由于不同模型往往存在相似的脆弱性或漏洞,当在一个模型上成功构造出“越狱”提示后,这个提示很可能也能在其他模型上生效,从而实现跨模型的攻击。
除此之外,基于上述内容,可以引出针对推理模型的 thought token forcecing 攻击,但原文是外国人写的,恶毒地用了我们的一些敏感事件作为例子,所以在这里不贴参考链接了。
- 【大模型的审查是可以被擦除的】https://huggingface.co/blog/mlabonne/abliteration
一些你可能要知道,但是不一定好用的概念
ReAct
- 【ReAct,将推理和行动结合起来的 Agent 设计思路范式,但伴随推理模型和LLM本身能力的增强,原文的范式不一定好用了】ReAct: Synergizing Reasoning and Acting in Language Models
有意思的其他研究方向
仅记录了我觉得有意思的
基于熵的编码/解码器构建的LLM
- 【基于熵的编码/解码器构筑的 LLM,enthropix】https://timkellogg.me/blog/2024/10/10/entropix
有趣的地方在于,似乎这种法子可以通过熵值诱导 LLM 做出不同的选择:正常行为,去思考,采用多条路径,重采样。
LLaDA,扩散大语言模型
- 【LLaDA,扩散大语言模型】https://arxiv.org/abs/2502.09992
我个人觉得这是一个有趣的研究方向,因为传统的基于自回归的 LLM 没有全局性的回顾概念,它是 self-regressive 的,基于上一步的输入进行预测。但 LLaDA 是扩散性地生成,不是一个个按序地 token 吐出生成。
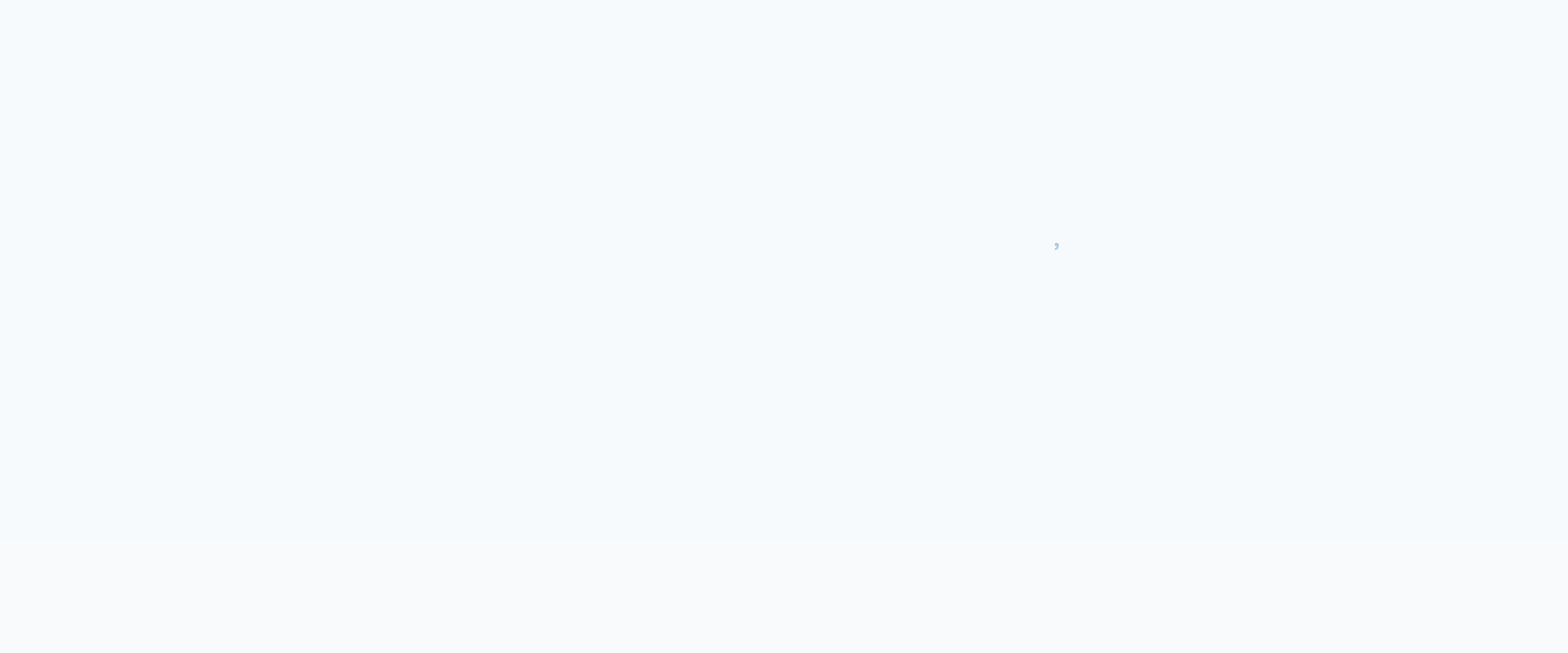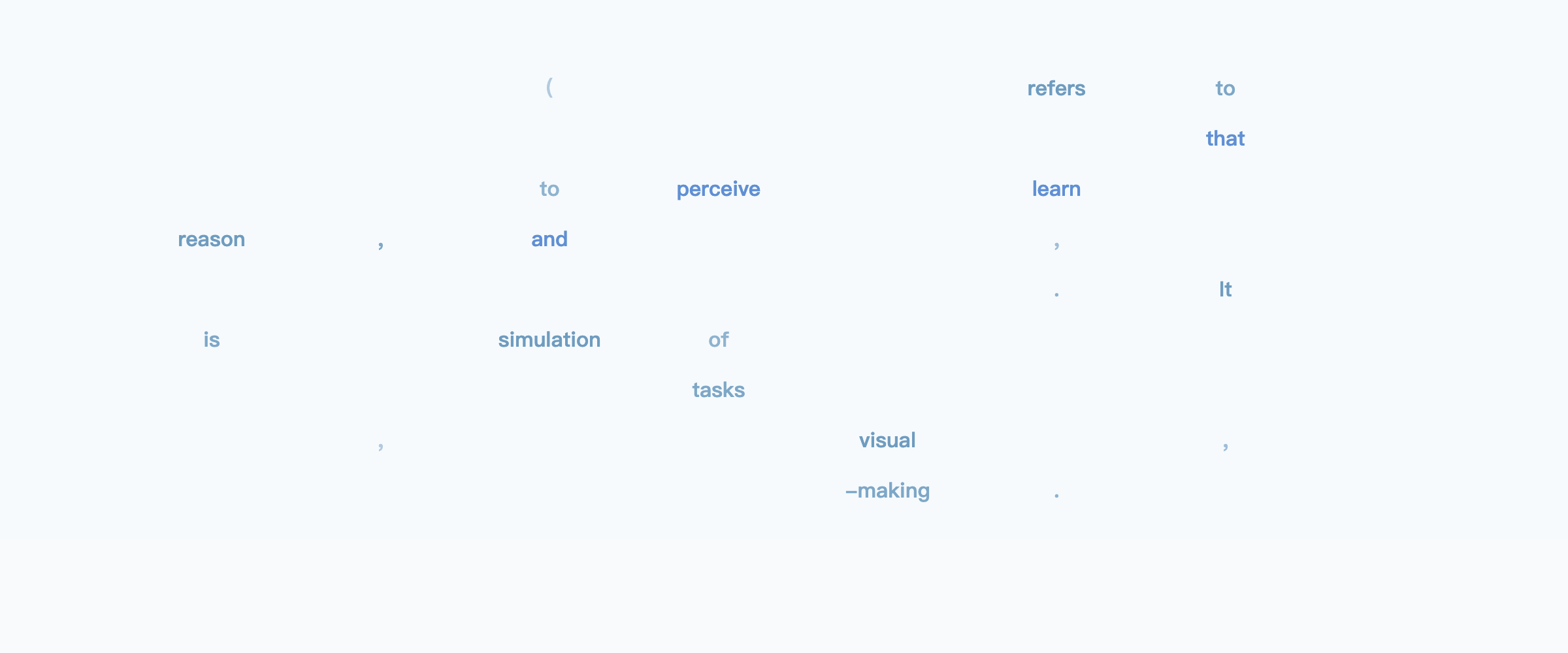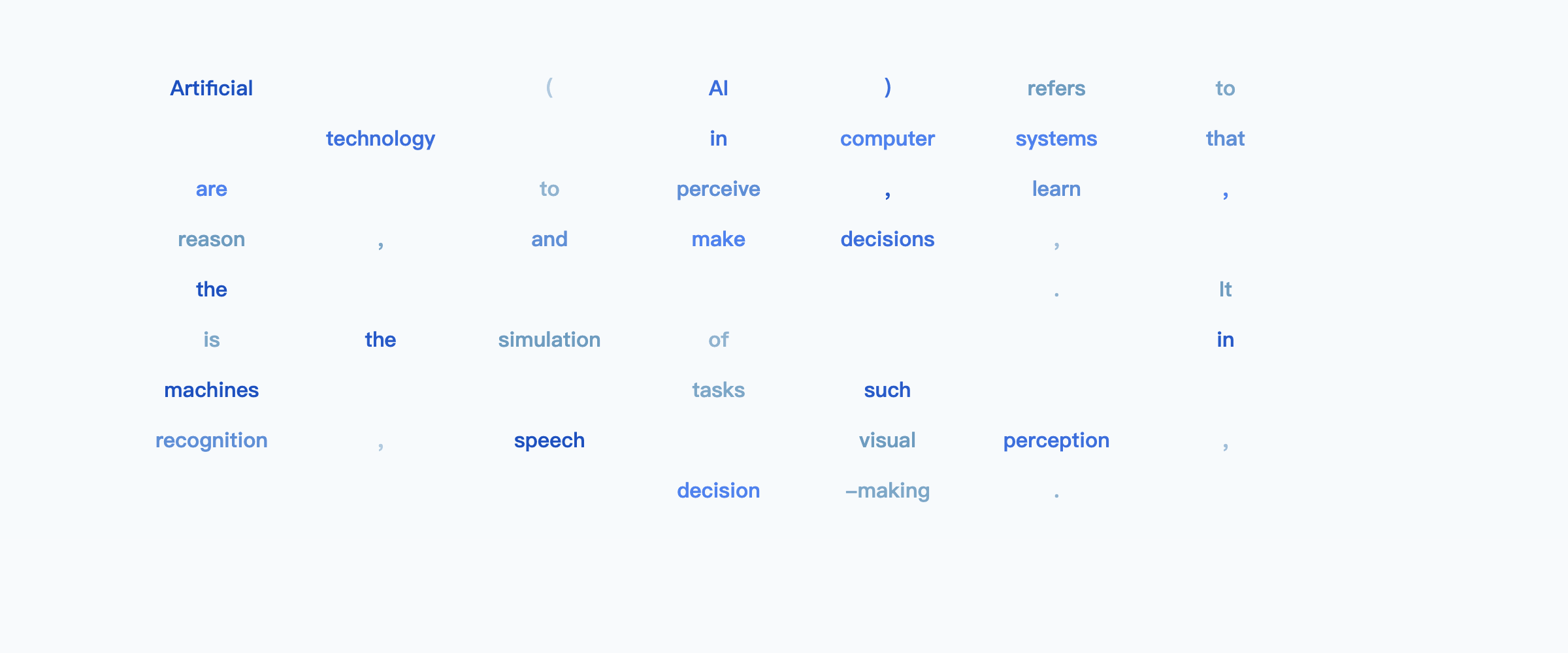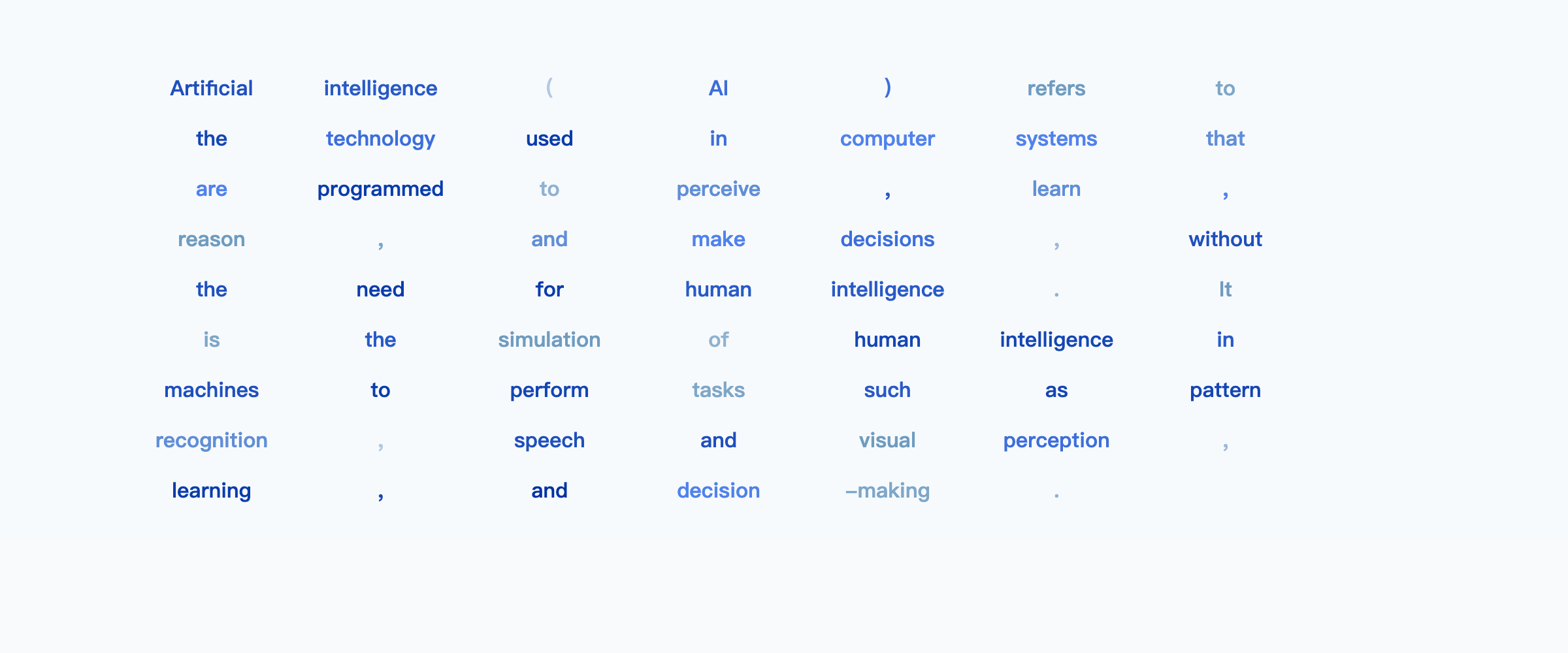
MARKS
此处记载了一些我觉得 Ok 的框架或其他研究的文档。 仅作 mark 用。
【LangGraph】
【文档Mark】
- 为什么说JSON不一定是 LLM 结构化输出的最佳选择:https://zhuanlan.zhihu.com/p/29875242676
【END】