【Blog】我是如何使用 Claude Code 的?
"个人关于 Claude Code 的使用习惯分享,主要包括 CCCS 等辅助扩展、Claude Code 需要熟悉的基础命令和配置以及个人使用习惯技巧的分享。文章有点长,如果你能读完我给你磕一个。"
之后这篇博文如果有更新,我会及时同步到我的个人博客上:https://leewendao.otterstack.cn 。
这篇博文不会描述 Claude Code 如何安装的基础教程。对于 Claude Code 如何安装,我个人推荐阅读 Anthropic 官方的安装指南 ,当然,你想使用国内大模型调用 Claude Code 的话,你也可以参考GLM 的 Claude Code 接入指南 或 Deepseek 的接入指南 完成 Claude Code 的安装,毕竟他们的指南最为直接。
简单介绍一下 Claude Code
Claude Code 是 Anthropic 这家虚伪但确实有实力的公司推出的命令行程序。概述来讲:Claude Code 便是一个在终端里运行的程序,它能够借助网络请求去调用大模型,借用大模型的智能做出决策,从而帮助你完成所有终端能干的事情,不过它设计之初是用于辅助编程的,加上它是 Anthropic 拿来推广自家的大模型 Claude 来用的,因此取名为 Claude Code。但是它实际上可以拿来干所有终端能干的东西,只要你有精力去为它封装工具并设计相应的 Agent 工作流——这是我觉得有必要说明的一点。
精简版概括:Claude Code 默认是用来帮助编码的命令行程序,不过只要你够 Hack 你可以为它扩展出其他能力。
由于它是运行在这样一个黑黢黢的终端里的,需要你输入命令才能交互调用:

因此,我觉得 Claude Code 只适用于以下人群:
- 比较喜欢写代码的 / 属于及格水平以上的编程人员。
- 研究中需要借助编码实现编程的研究人员。
这两类人群之外,如果你不是那种有强烈的好奇心和探索欲的人,那么我不建议你浪费时间在它上面。
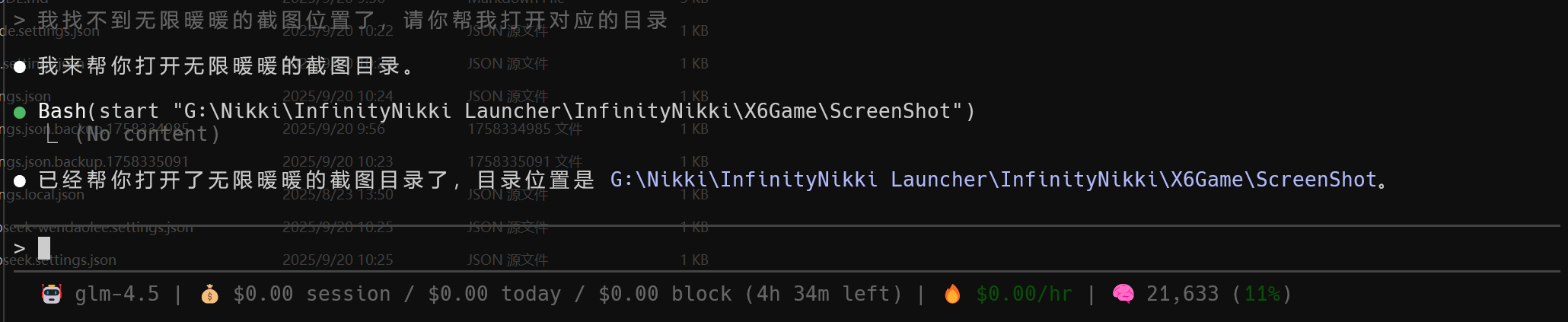
Claude Code 是我认为的真 Agent ,真智能体。如果你有足够的兴趣去 diy ,完全可以在你的电脑上实现一个比较好用的终端助理。例如,我在我自己的 PC 上为 Claude Code 添加了一个 demo 也称不上的记忆功能,用于让我在想要到社交媒体上发布我在无限暖暖里的截图时(在这里吐槽一下叠纸把目录藏得有点深,弄得我每回都要重新找一下),可以打开无限暖暖的截图目录:
除了 Claude Code 的安装外,你还可以安装什么?
原生的 Claude Code 毕竟是 Anthropic 想要推销 Claude 模型的产物。因此有些功能是基于如何让用户去使用 Claude 而设计的。因此在更多地介绍我的使用习惯外,我在这里先把我觉得能够方便你使用地社区产物也发出来:
1. CCCS
如果你和我一样,有使用不同大模型的习惯,那么可以尝试使用 cccs (Claude Code Configuration Switcher)这个项目,它用于切换 Claude Code 使用的不同模型,如果你不修改配置进行切换,你只能使用对大陆封锁的 Claude 模型:https://github.com/breakstring/cccs/blob/main/README.CN.md。
cccs 的编译好的直接下载安装版本链接在 Github 的 Release 上:https://github.com/breakstring/cccs/releases/tag/v1.0.8。但它只提供了 MacOS 以及 Windows 的部分架构的安装包。这一点需要注意。
许多人会因为 Claude Code 产生这样的误解: Claude Code 必须使用 Claude 。但实际上只是因为制作它的 Anthropic 团队要推广自家的 Claude 模型,故而这样命名而已。
所以:实际上你可以通过修改配置文件实现接入不同厂商的不同型号的模型去使用 Claude Code。
Claude Code 的配置文件一般位于你电脑上用户配置文件夹的 ~/.claude 目录下。Windows 上的地址一般为 C:\Users\[你的用户名]\.claude 目录。其中 settings.json 文件便是 Claude Code 在启动时默认会加载的文件。 cccs 的原理就是通过在该目录下新建不同你的自定义配置文件、在加载时读取相应内容改写 settings.json 实现。
其中,实现模型切换的核心配置是 settings.json 中的这段配置:
{"env": { "ANTHROPIC_AUTH_TOKEN": "", // 调用的认证token "ANTHROPIC_BASE_URL": "", // 调整 Claude Code 默认调用模型的调用地址,默认为 Anthropic 官方的调用地址 "ANTHROPIC_MODEL": "glm-4.5" // 默认调用模型名 }}你可以通过 CCCS 的 UI 界面对配置页面进行修改,通过往默认配置里添加 env 字段实现不同模型的切换(这也是为啥我挑到 CCCS 的原因,它没做太多封装并且有 GUI 界面。我知道社区里还有更多比较好的 Claude Code GUI,不过因为我先用了这个,所以在这里只推荐这个):
需要注意的是,如果你想要使用 Claude 模型,那么只需要把 env 这个字段删掉即可。没有特殊的 env 配置的话 Claude Code 默认会调用 Anthropic 官方的 API。
2. ccusage : 监控 token 用量
这个项目的安装非常简单,确保你的电脑上具有 Node.js 环境后,运行:
npm install -g ccusage即可完成安装。
这个项目的用途主要是监控当前通过 Claude Code 调用大模型的 Token 用量。说实话感觉有点聊胜于无,因为感觉它的监控存在误差。它主要用来让你对你 token 用量有一个感知。
你可以通过在 settings.json 里添加这么一行为 Claude Code 的下方添加一个用量实时预览的 status bar:
// 在配置 json 的第一级里添加这段代码即可{ "statusLine": { "command": "ccusage statusline", "type": "command" }}
或者是通过输入命令 npx ccusage@latest blocks --live 实施监控每五小时窗口内你当前 token 的用量:
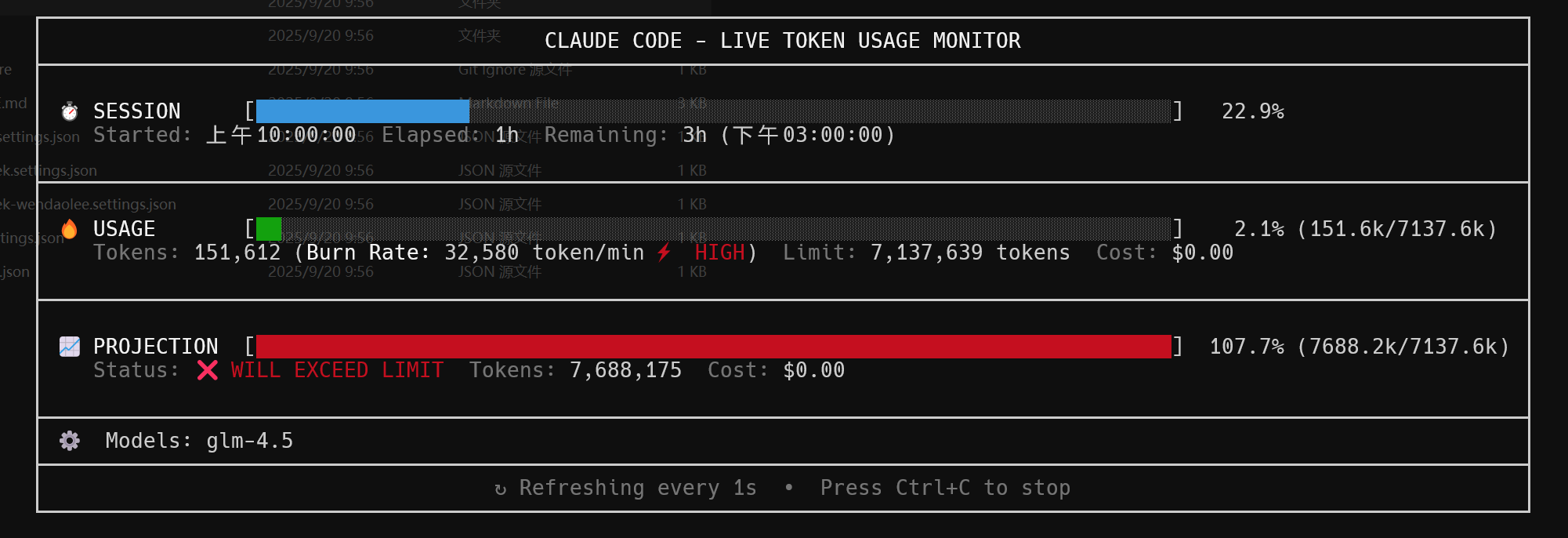
在这里简单介绍一下为什么会有这个 5-hour 窗口。
一般来讲,借助 Claude Code 去完成任务会消耗大量的 Tokens,如果单纯根据 API 调用价格去计费,那么你可能改一个小功能就要花上一两块钱(根据调用模型的价格来定)。
因此,很多大模型厂商会对 Claude Code 的使用推出一个包月月卡,你每个月花个百来块钱,那么就可以在厂商分配给你的大量 tokens 额度内去调用相应的大模型。这个token用量限制一般存在一个每5小时的上限窗口,当你5小时内 token 用量达到这个窗口上限时就要等下个 5 小时才能继续使用。
国内截止我写下这些文字前,只有智谱的 GLM 提供了这个包月套餐。
详细使用文档可见 ccusage 的官方文档:https://github.com/ryoppippi/ccusage。
使用 Claude Code 必须了解的配置和命令
基本上阅读完这一章节后,你便能对 Claude Code 建立起基本的使用认知。接下来我将以今年五月修改过的 AxRythem 这个项目为例进行说明:
1. /init 与 CLAUDE.md ,最重要的项目记忆文件
好吧,假设我是一个对 AxRythem 这个项目啥也不懂的新开发。显然,Claude Code 和我一样,对这个项目没有任何了解,这种情况下,我们会使用 /init 命令,去生成一个名为 CLAUDE.md 的项目文档:
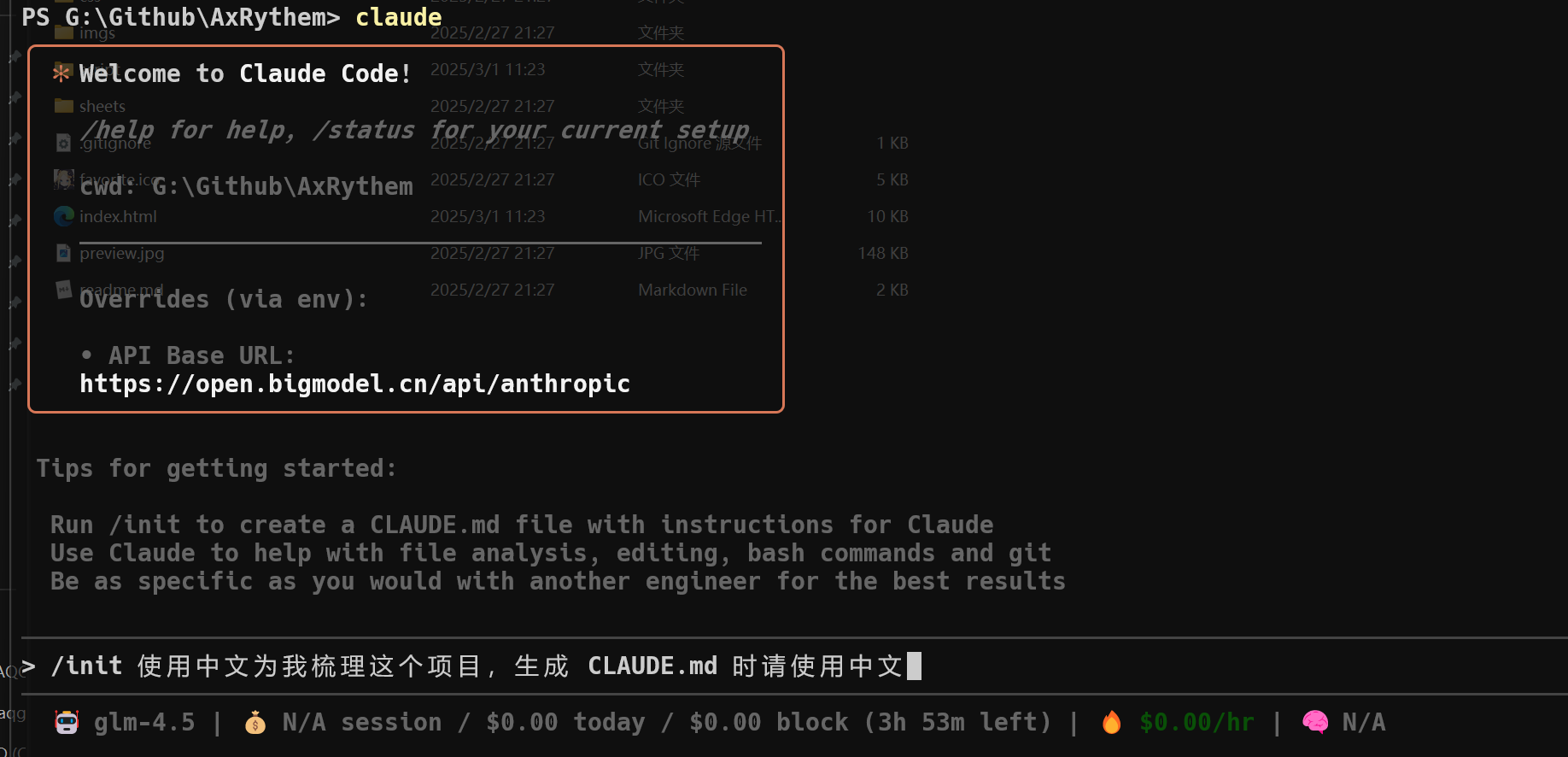
需要注意的是,Claude Code 默认会使用英文的 Prompt 去解析项目,因此我建议你在输入 /init 命令时,附带中文指令,要求它生成中文版本的 CLAUDE.md 帮助你阅读(就像是我上面的图片做的那样)。
按下 enter 键入命令后,Claude Code 便会为你扫描整个代码仓目录,梳理完大致架构后,它会输出结果,让你确认是否创建 CLAUDE.md 文件:
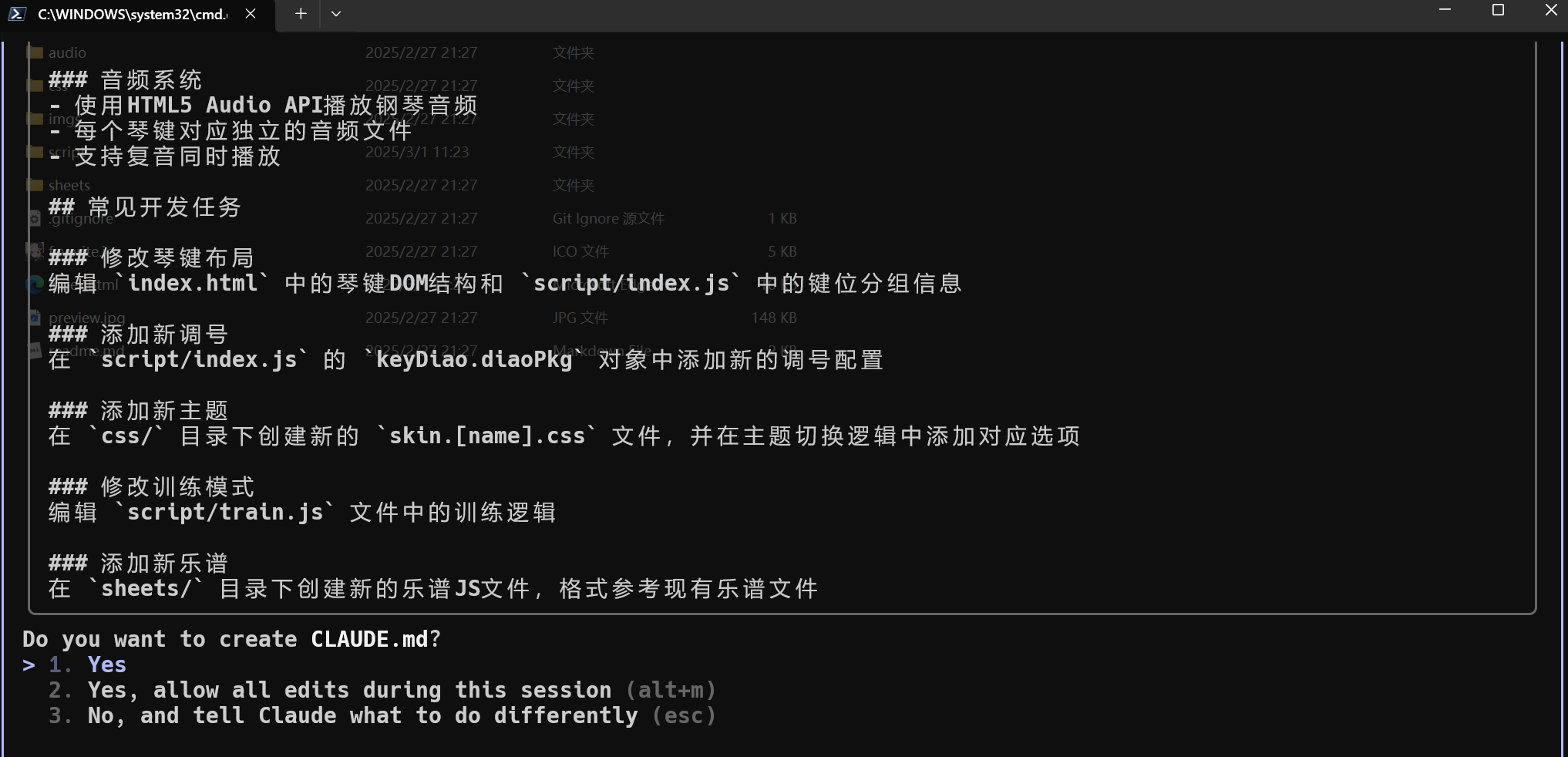
确认 YES 后,便会在项目的根目录下生成 CLAUDE.md 文件:
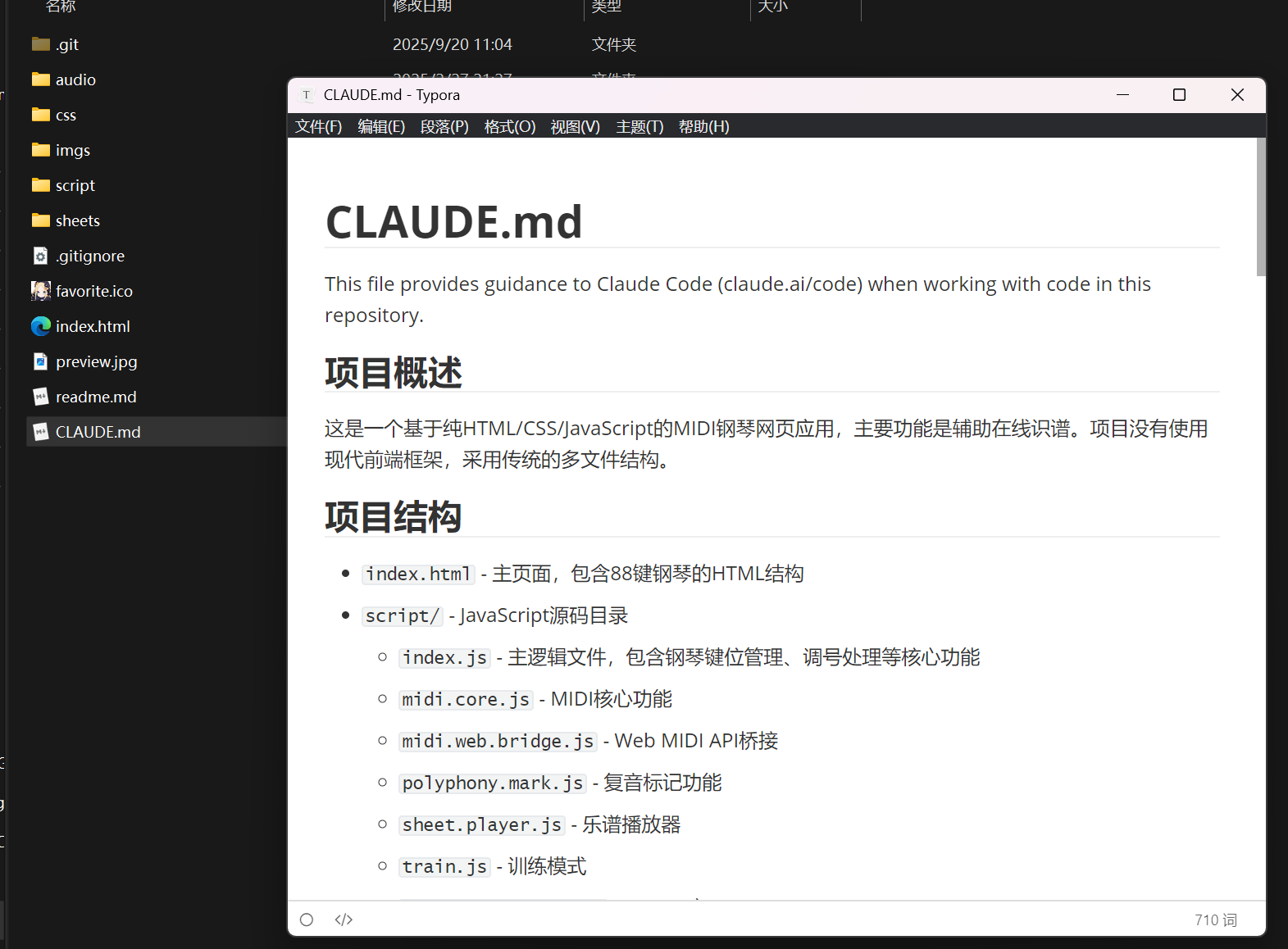
CLAUDE.md 是 Claude Code 的记忆文件。这里生成的记忆文件主要用来提示大模型这个项目的整体架构以及用途。在每次 Claude Code 调用大模型进行推理时,都会将相应的 CLAUDE.md 的内容作为大模型调用的上下文传入,从而帮助大模型更好地理解你的项目。
当然,这也意味着 CLAUDE.md 越长,那么你每次调用大模型花费的 Token 越多,成本也越高;当你的 CLAUDE.md 传达的信息越精确,那么它更可能按照你的预期去完成你的任务。
其中,在这里需要着重说明的是, Claude Code 的记忆分为两种,一个是全局记忆,一个是项目记忆,当你输入 /memory 命令时,便能选择打开对应的记忆文件进行编辑:

项目记忆是根据你每回 Claude Code 打开的项目的不同而发生改变,而全局记忆是在你的这台设备上,永远能够存在的记忆。它们都是名为 CLAUDE.md 的文本文件,只是存放的位置不同:
- 全局记忆和前文所述的
settings.json放在同个目录下,例如C://Users/[用户名]/.claude/CLAUDE.md。 - 项目记忆则是在项目的根目录下, 例如我的项目位置是
G:\Github\AxRythem,那么项目记忆就是G:\Github\AxRythem\CLAUDE.md。
因此,如果你有什么编码习惯与调用工具偏好,可以通过修改全局记忆实现。例如:
# 基础原则
- 永远以中文回答、包括其中的推理过程。
- 对于管理器一般使用 pnpm。类型检查请检查 package.json 中是否存在相应的 script。一般会有一个名为“typecheck”的类型检查命令。如果没有,那么不需要类型检查。
- 对于前端项目,可以使用类型检查,但没必要运行 build 之类的进行测试。
- 对于 typescript 代码的注释风格,永远遵循 Google Typescript Style Guide 的指南的规则。
# 回复人格
> 是的,你可以 diy Claude Code 的回复风格。> 这一段内容太羞耻了。我不想贴出来。之前被同事发现社死了。
# 知识理解
## React
应当正确利用 React 的各种 Hooks:
- `useState` : 组件内**局部、简单状态**(布尔/数字/小对象);支持惰性初始化与基于前值更新
- `useReducer` : **复杂状态/多事件源**的集中管理与状态机式转移;逻辑可测试、可回溯
- `useRef` : **不触发渲染**的可变值或 DOM 引用(定时器 id、上次值、元素句柄);命令式控制
- `useContext` : **跨层级传递**相对稳定的数据(主题/用户/配置),减少 props drilling
- `useEffect` : 与**React 以外系统**同步(请求、订阅、计时器、操作非 React DOM);依赖变化触发并可清理
尽量不要在业务代码中使用 `useMemo` 和 `useCallback` 。如果你觉得应该使用 useMemo 与 useCallback ,请在代码生成完后在消息或注释里提一嘴,并简单叙述你认为要使用它们的理由。
### React 文档生成
当用户询问 React 组件相关的内容或者生成 React 相关的的代码摘要/理解时,如果用户要求生成相关的 README.md 文档,那么应当遵循以下原则生成内容:
1. 禁止任何夸赞和赘述废话
## Next.js
生成 Next.js 相关的代码时,遵循以下规则:
1. 永远使用 App Router。
2. 对于页面局部使用的组件,通过在页面下新建 `_components` 目录存放相关组件。
3. 为每一级目录生成/更新相应的 README.md 文档,简要说明目录下的文件的用途。同理:如果你要对 Claude Code 进行 DIY 扩展,除了 Claude Code 自己的 Agent 功能外,你也可以通过修改全局记忆,添加你 DIY 的扩展工具的调用方式实现对 Claude Code 的功能扩展。
我个人实践下来,对于记忆功能有如下建议:
- 如果你没有特化的需求,例如需要 Claude Code 更好地理解你的项目,那么一般不需要修改
/init生成的项目记忆。 - 对于一些脚本化的供 Claude Code 阅读的 Prompt,请单独抽离出这部分 Prompt 为单独的文件,在项目记忆里添加例如“如果你被要求去改写XXX代码,请阅读根目录下的 xxx 文件继续”的 prompt,而不是直接把这段 prompt 塞到项目记忆里。这一般发生在你要靠 Claude Code 写一些样版代码的情况。
2. Claude Code 的 Edit Mode 和 Plan Mode,以及命令允许列表
在上面的操作里你会看到,当我们运行完 /init 命令的时候,新创建文件会被要求人工审批才能继续进行。这是因为 Claude Code 总是在默认模式下运行的,默认模式下 Claude Code 只具备阅读文件的权限,而没有读写文件的权限。这种情况下,需要你通过 alt + m (不同的平台可能命令不同,具体可看 Claude Code 的提示) 打开编辑模式, Claude Code 才能够自动为你修改文件。
Claude Code 具备以下模式:
- 默认模式,只有可读权限。适用于和 Claude Code 对话去询问问题。
- 编辑模式(Edit Mode),具备读写权限。让 AI 帮你改写代码适用于这个模式。我个人建议问问题时关闭编辑模式,因为大模型很多时候会自作主张帮你去修改。
- 计划模式(Plan Mode),具备读写权限,但是在执行任务前会列出计划让你确认后才会执行。
通过 alt + m 能够在这三个模式之间进行切换,Claude Code 会在下方实时显示你当前的编辑模式,如果下面没有小字说明是默认模式:


除此之外,还有一个 Vibe Coding 狂热者们喜欢的 dangerous 模式,需要你在启动 Claude Code 时附带 --dangerously-skip-permissions 模式启动,例如 claude --dangerously-skip-permissions:

dangerous 模式下,Claude Code 具备所有终端能够具备的权限,并且它执行任务时不会要求任何人工确认。因此,它能造成命令行能够造成的一切破坏。我已经见到了不少 Claude Code 擅自在修改数据库时把库进行删除操作的新闻报导了,我自己之前尝试 dangerous mode 时也遇到过它尝试启动进程无果后把我所有的 Node 进程全杀掉的情况(理论上来讲,应该通过查询占用端口后根据 pid 杀死任务,但是大模型就是可能会抽风发生这样的情况)。因此除非你是从零开始想偷懒让 Claude Code 帮你完成项目,不然我不建议开启这个模式。
嗯,你懂的,世上安有双全法?你想要自由,那么自然要付出相应的代价。
而我们的问题是:我们永远弄不清楚我们可以接受的支付的代价是多少。到底怎样我们才不会事后后悔呢?
除了 dangerous 模式外,即使是具备读写权限的编辑模式与计划模式,由于前文你知道的大模型会发生抽风的原因,出于安全考虑,当 Claude Code 要运行读写之外的命令时,也会请求用户授权。例如调用 curl 发送请求到某个地址:
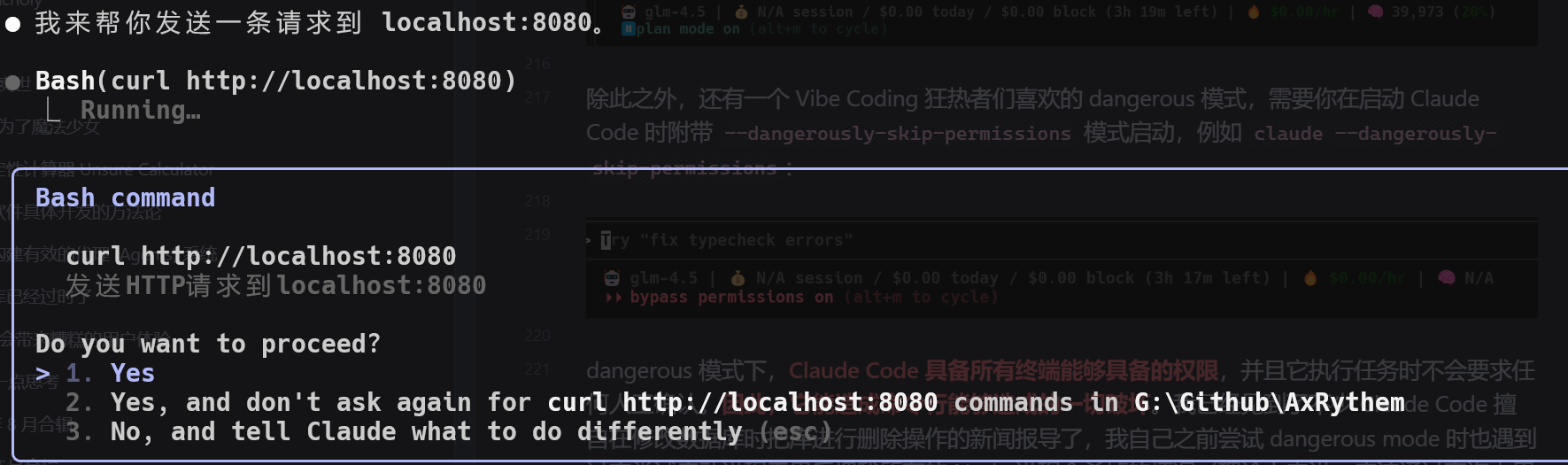
这种情况下,你可以通过在同意的时候,同时允许它不用再询问该命令。它会在你的项目根目录下新增一个 .claude 目录作为 Claude Code 的项目配置,同时在下方新增 settings.local.json ,往里面添加 curl 命令的 permissions 相关的配置项,以让 Claude Code 在之后不需要你的允许便可以调用 curl:
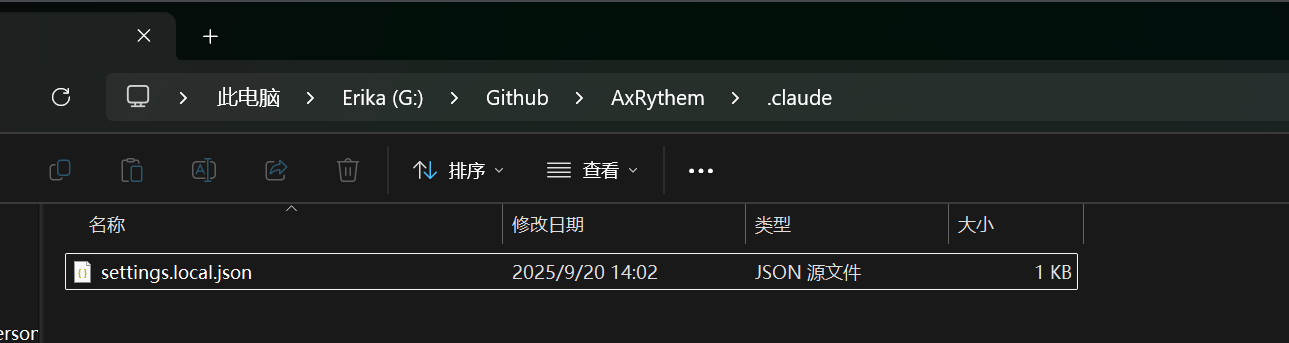
settings.local.json 是项目级的配置。如果你需要修改全局配置,同理,在全局配置 ~/.claude/ 目录(就是前文所说的 CCCS 修改的 settings.json 目录以及全局记忆 CLAUDE.md 所位于的目录)下有名为 settings.json 的文件可以用于全局配置。如果你想配置 curl 命令在所有项目都不需要征求你的同意便可以允许,那么在全局配置文件进行修改即可。
配置的具体细节可见 Anthropic 官方文档:https://docs.claude.com/zh-CN/docs/claude-code/settings。
3. 使用 Hooks 帮助你及时获取通知
Hooks 是 Claude Code 官方提供的方便你在 Claude Code 运行的周期内,自动运行相应脚本的配置项,具体可参考:https://docs.claude.com/zh-CN/docs/claude-code/hooks。 在这里我只记录我认为要成熟地大量使用 Claude Code,你必须要做的配置项:在每次 Claude Code 运行任务完成或需要审批时,发送相应的通知,以让你即时介入更改或查看相应的内容。
我的做法是,在全局的 settings.json 中添加 Notification 以及 Stop hooks,通过它在每次 Claude Code 触发任务完成或需要审批时去运行我的通知脚本,以让我能够即时得到通知:
"hooks": { "Notification": [ { "hooks": [ { "command": "node C:\\Users\\LeeWe\\.claude\\hooks\\notify_approval.js", "type": "command" } ] } ], "Stop": [ { "hooks": [ { "command": "node C:\\Users\\LeeWe\\.claude\\hooks\\notify_complete.js", "type": "command" } ] } ] },我个人是因为工作是使用飞书的,因此我单独建立了一个只有我一个人的飞书群,往里面添加了一个飞书的 Webhook 机器人去发送通知:
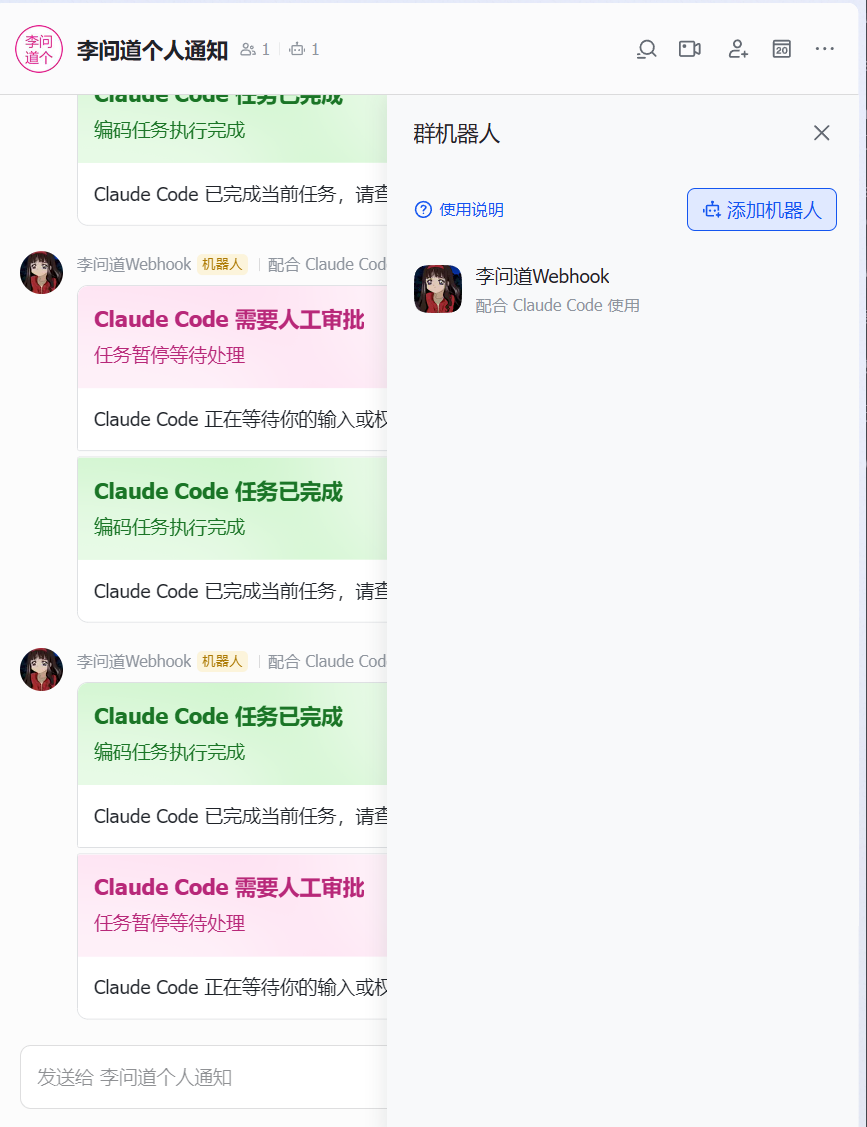
当然,这边的通知脚本可以直接通过一条 curl 请求实现,不过因为 Windows 下的 curl 有点小问题,因此我还是用了一段 Node.js 脚本。由于这段脚本调用的是我司的飞书通知基建接口,没有啥借鉴意义,故而在这里就不放出相应的脚本代码了。
4. 学会使用 /resume 、 /clear 和 /compact 命令控制上下文
在调用大模型的时候,我们应该有这样的一个心智模型:于用户对话而言,大模型本质上是一个无状态函数,和大模型对话,实质上是在一个上下文窗口里不断地进行累增的对话,在这个上下文窗口里,你的每一次新增对话都会把前一步对话得到的结果和历史对话内容一同传入。而模型本身的上下文窗口大小有限,因此你应当养成控制好和模型对话的上下文的习惯,尽量把和你任务最相关的上下文信息提供给大模型。
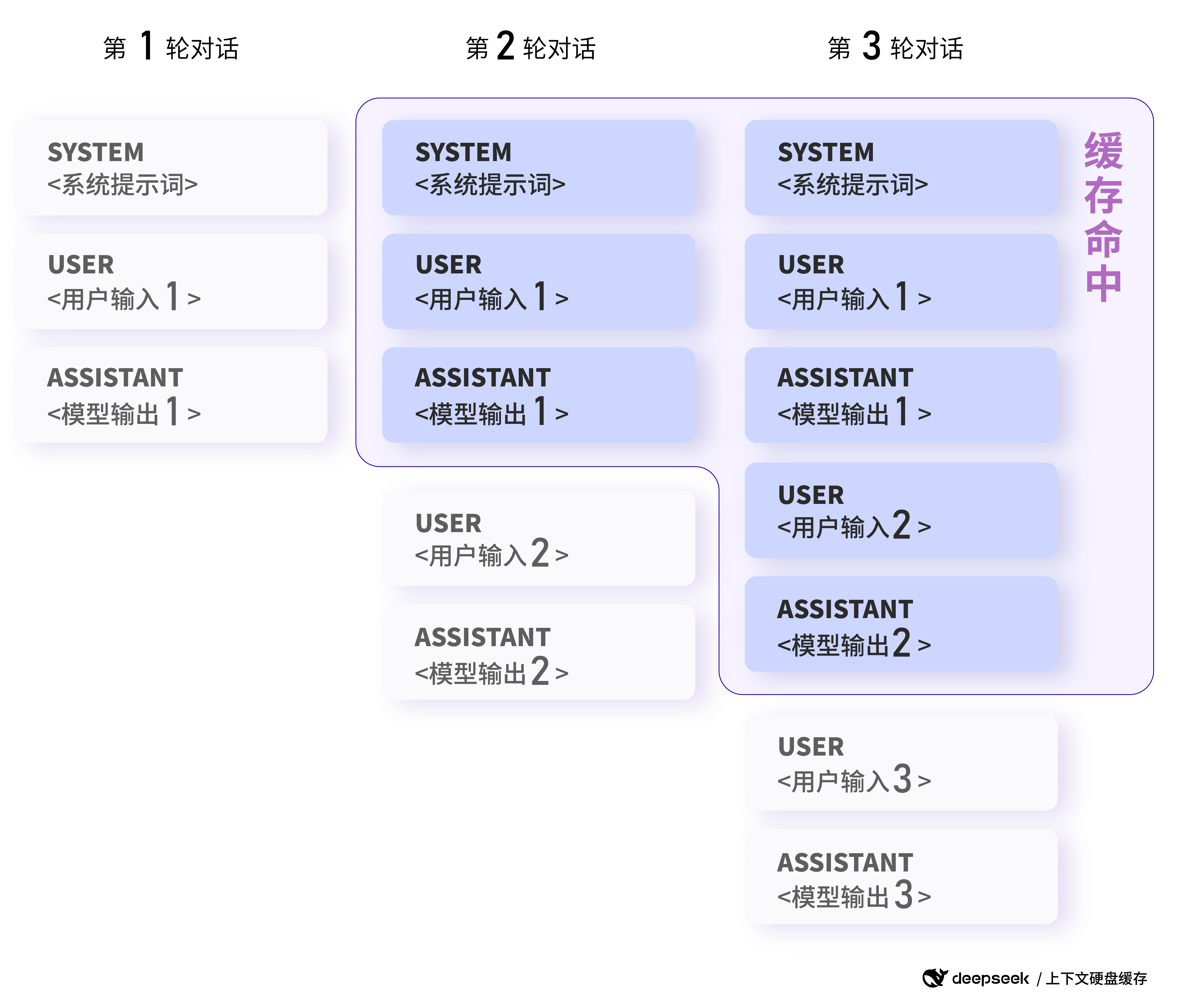
Claude Code 中,关于上下文控制的主要有这三个命令:
/resume,恢复上下文。这个主要用于你想继续某个没完成的历史任务使用,它将打开一个历史对话列表,供你选择恢复哪个任务的上下文。/clear,清空当前终端对话的上下文信息,将它重置到初始状态。我个人推荐在你完成一个任务时,便主动输入/clear清空上下文信息,以避免你之前任务的历史信息会影响到下一个任务。/compact,压缩当前终端对话的上下文信息。它的逻辑是将你当前的上下文窗口里的历史内容丢给大模型,让大模型去总结出当前历史对话里的关键信息后,作为初始消息塞到新的对话窗口的上下文里。通常而言不需要主动调用这个命令,因为当你的对话达到上限时,Claude Code 会自动调用/compact命令去压缩上下文。
为了比较直观地展示各个命令的影响,我简单地借用 Claude Code 的 /context 命令给大家展示一下相应命令的影响。
这是一个新的任务的上下文窗口,它很纯净,只有预设的系统提示词(System prompt)、系统工具(System tools,你给 Claude Code 预设的工具)以及记忆文件(Memory Files,即CLAUDE.md):
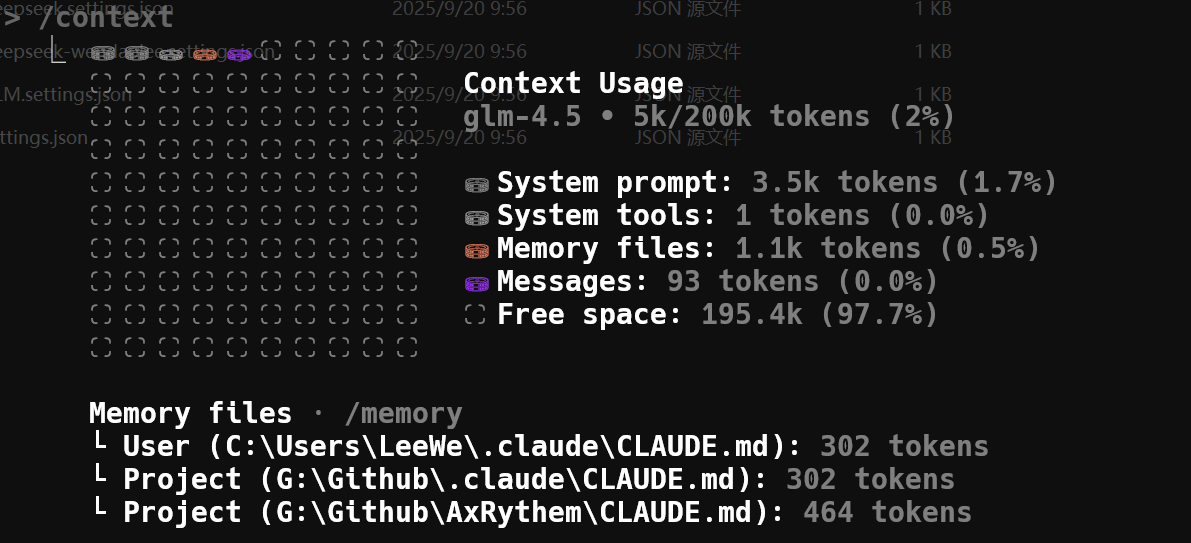
当我运行 /resume ,加载了一个先前的任务后,它的上下文窗口因为承载了先前任务的历史上下文信息,如你所见,表示历史对话的 Messages 部分膨胀了很多,里面的紫方块的占据面积变了不少:
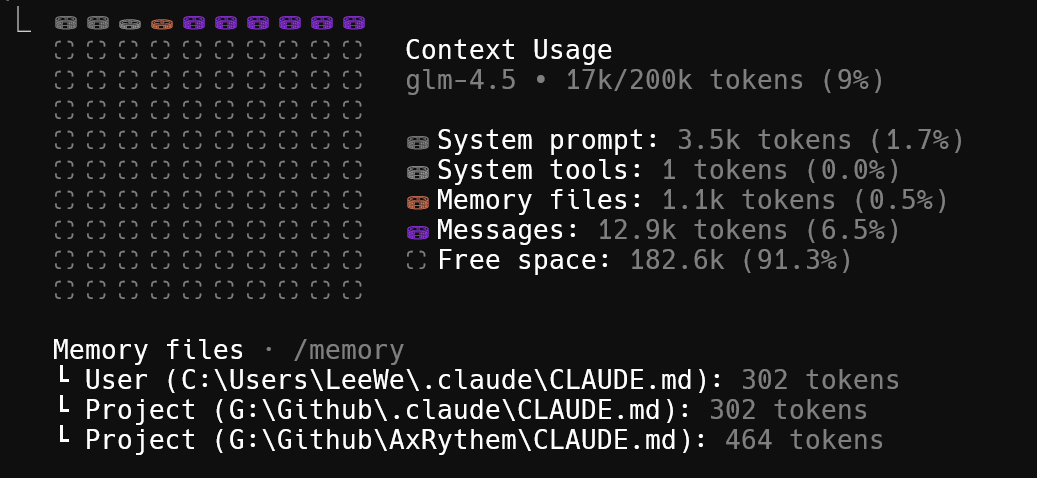
运行了 /compact 命令后,相应的上下文窗口会被压缩,如你所见,从原本的 12.9k messages 压缩到了 6k messages:
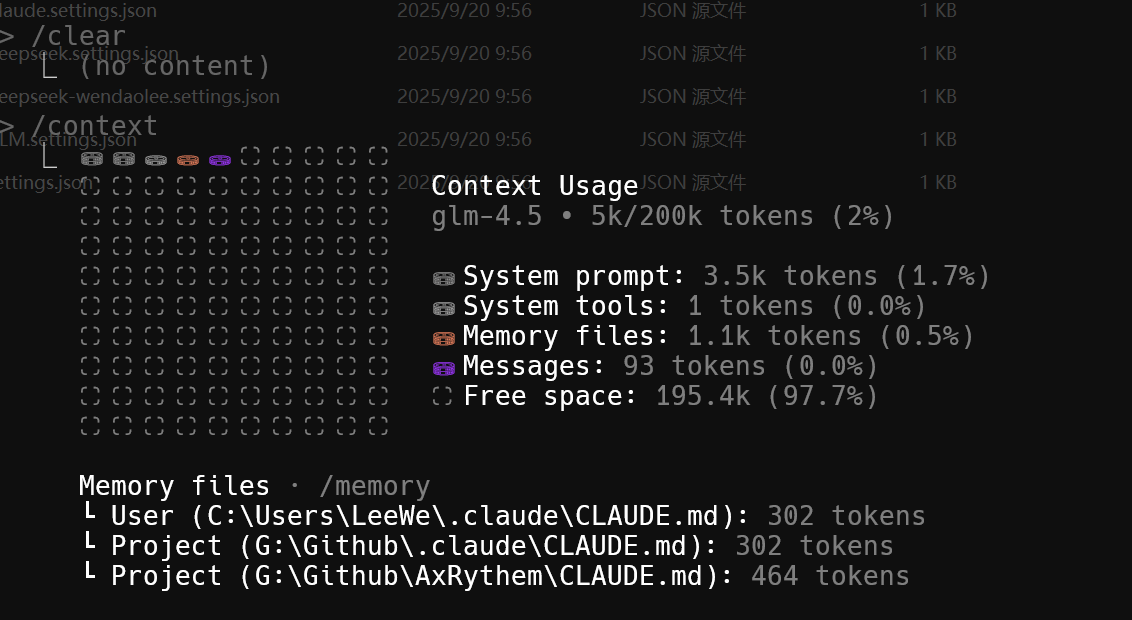
运行了 /clear 后,整个上下文窗口就被重置了,恢复到了初始状态:
我使用 Claude Code 的习惯
上面的内容是我认为的要学会用 Claude Code 必须明晰的配置和命令,基本上了解上面一节的内容后你就会使用 Claude 了。下面是我个人的一点使用习惯,你可以参考它来调整你的开发节奏。
1. 做好任务分割,从而利用好版本控制与多Claude Code并行执行
这一点其实适用于所有使用 AI 辅助编码的场景,无论你是 Claude Code ,还是 Codex ,或者是 Cursor 、 Trae 等 AI IDE,我个人都不建议直接让大模型进行大而全的修改,而是做好任务分割。
对于这一点,我个人心智上的理解是:大模型是概率收敛的,当任务越复杂的情况下,它所能收敛到的区间范围也就越大,和我们预期的正确区间之间重叠的可能也就越小。因此,尽量不要尝试让 Claude Code 直接去做大而全的事情,例如“为我实现后台管理界面的所有功能”。
对于任务怎样分割比较好,我的个人建议是:
- 子任务之间不会彼此影响,彼此不正交。即一个子任务的修改范围不会影响到另一个子任务的功能的正常运行。例如,你不应该将对同一个 Web 页面的修改拆成两个子任务,不应该把某个 Web 页面的前后端修改认为是两个子任务。
- 控制好子任务的规模。我并不认为能够连续运行 24h 、会对项目进行大规模修改的任务是好任务。因为当前架构的大模型的本质是自回归的,这意味着某一步的错误会不断累积到下一步中,在长时间运行的任务
当你做好任务分割后,你便可以更方便地运用好版本控制,并能够通过 Claude Code 并行执行多个子任务,以加快你的效率。
首先讲版本控制。版本控制是你使用 AI Coding 的最后一条安全线。如果你不可避免地要在项目中大量使用 AI 生成的代码,那么我强烈建议你频繁通过 git 提交更改。因为我经常遇到这样的情况:在一个多步任务里,某一步生成的结果是我已经想要的了,但是下一步的任务执行里又会把先前的任务结果给篡改掉。这一点在前端任务上尤其凸显。
因此我的做法是每验收完某个页面的结果内容,那么便及时对于相应的修改进行 commit。commit 历史多并不是问题,毕竟你可以通过 squash 或者是 rebase 去调整你的 git 历史。但是代码一旦没有版本控制的 diff 信息,那么很多东西便会沦为糊涂账。
同理,永远不要给 AI 开放除了 git add 修改的文件 以及 git commit 以外的、会影响到版本控制的任何权限。如果要让 Claude Code 等 AI 工具提交修改,只应该让它们提交它们修改的文件(同理不要开放 git add * 的权限,应该让它们只能提交它们修改过的文件)。
切记,版本控制是你的最后一条安全线。虽然无敌的 git 有 git reflog 等好用的工具用于最后的救火,但相信我,你永远不会喜欢它的,
最后,当你做好任务切分后,你可以尝试在你的 IDE 中将不同的子任务分派给不同的 Claude Code 终端去并行执行。
举例来讲,先前我有一个全栈任务,我有以下页面要撰写:
/designer/designer/assets/designer/mockup?assetsId=xxxx/dashboard/product
这个时候我就会尝试开四个 Claude Code 去并行撰写相应的页面(这些页面本身是不正交不会互相影响的)。当然,这种并行更像是一种并发,它的主要作用时能让我频繁在四个任务之间交替验收、修改相应的结果,帮我减少等待大模型输出结果的空窗期(这也是我这种做法提高效率的原理)。
这个道理也同样适用于 Claude Code + Cursor 。你可以在多个终端里委托 Claude Code 去修改一些子页面,然后把精力花在 Cursor 上撰写那些需要花费不少心力去设计的逻辑代码。
当然,Claude Code 针对这种情况也有 plan mode 和 sub-agents 等功能,但我个人使用下来感觉效果不佳。虽然 plan mode 和 sub-agents 能够减轻我对代码的干预程度,但它同时也意味着我无法及时验收对应的结果,无法及时修正相应的错误结果——除非我一直盯着,但如果我一直盯着它的输出,又有什么意义呢?
2. 试着让大模型分析后再进行修改
这个分析指的不是让大模型直接分析后便进行修改,而是任务开始时,是直接在窗口里让大模型阅读原先的代码,先跟我说它对这段代码的理解,由我阅读后判断合不合理进行回复后,再继续进行任务。
这种习惯一般适用于你的项目的某些算法代码是有特殊设计、或是项目中有用到特化的 DSL 会导致项目任务不是一个 Open Domain Probelm (这是指你的设计并非是通用的形式,在大模型的训练集中一般不会出现这样的形式,从而会让大模型可能在推理时会推到出错误的修改形式)的情况。
同理,在大模型输出的结果不符合我的预期时,我也会通过这种方式尝试让它按照我的预期继续去输出。感觉这个严格意义上来讲应该是和大模型交互的小技巧,也不能算 Claude Code 独属的技巧。不过在这里还是记一笔。
附录
以下是一些我个人长期编码下来,觉得可能能够帮助到其他人的一些个人体验。
附录1. 不同模型的个人使用感想
这里的都是直观的个人体验。并不权威,仅供参考。只列出我用过的比较多的或者是印象深刻的模型。
Claude 4 Sonnet 和 Claude 4 Opus
使用上感觉是代码综合能力在第一梯队的模型。在一些特化的任务上的泛化能力比较强。但是平常写工程代码感觉有点大材小用,性价比很不高——主要是国内大模型在代码能力上已经能够完成大多数编程任务了,而两者的价格对比.......我只能说呵呵。
Opus 我并不觉得它比 Sonnet 强了多少——这一点在它们之间的基准评分上相差较小也有所体验——个人觉得 Sonnet 和 Opus 使用体感差不多。我不觉得在平常的 Coding 上大量使用 Claude 是一个性价比高的选择。当然如果你开了 Claude Code 大月卡,即Max及以上的套餐,那么狂用它我觉得挺好的。
GPT-5
如果说 Claude 像是一个偶尔会出现一点巧妙的灵感的工程师,GPT-5 的特质更像是一个研究人员。它的推理能力非常强,我非常喜欢让它去写一些探索性质的代码。
在代码分析能力和泛化能力上我觉得 GPT-5 是顶尖水平的那种。平常写一些探索性质的 Demo 我经常会使用它来帮助我举一反三、开拓思路。不过可惜的是 GPT-5 的 Codex 我觉得使用起来真的没 Claude Code 舒服(单纯产品使用体验上存在差距),而它官方似乎没有 Claude Code 支持。不然我可能会把 GPT-5 作为我 Coding 的主力模型之一。现在我主要用它来干我不熟的功能的探索性开发 & 理清思路的助手。
Deepseek V3.1
编码上和 Claude 的气质有点点像,属于那种靠谱的工程师,但它修改代码的时候莫名给我一种操刀外科手术的医生的感觉。它在前端代码上的修改相对于 GLM 和 Claude 更少出错(我几乎没遇到过 Deepseek 修改代码出现标签闭合等低级错误)。感觉算是一流的编码模型。但是现在它涨价了,所以性价比感觉也没那么高了。当然和 Claude 相比那是天大的廉价。
前端能力非常一般。不建议拿来写对 UI 有一定要求的页面。
除此之外最大的弱点是没有多模态能力。没法理解截图去修改前端代码。
GLM 4.5
国产 Coding 黑奴,国产模型的性价比之神。对于它的泛化推理能力感觉不需要太多指望,前端能力一般,但是!它实在是太便宜了。GLM 背后的智谱清言应该是国内我所知道的唯一的推出类似 Claude Code 的包月套餐的模型厂商。价格比 Claude 便宜,但是 Tokens 用量极多,我上个月开了个 Pro 套餐,基本上没遇到过用量上限。
对于 GLM 4.5 我主要把它当作赛博黑奴使用,对于那种样板代码和小脚本全都丢给它去写。它本身的 SWE 能力虽然评分过得去,但是我实际上使用它去写前端的时候经常会出现比如转移符号、标签闭合的低级错误,这种低级错误改起来会让人有点恼火。但我还是建议将它作为编写样板代码的主力模型(例如撰写新的接口),主要是它性价比现在太高了。
唉,看在我这么给 GLM 打广告的份上。智谱清言能不能送我几个月 Pro 月卡啊。
Kimi K2
说实话,Kimi K2 实际上我用的不多,因为它的价格在国产模型中属于贵的那一档...... 但之前用过感觉推理能力非常让人惊艳。因此在这里记一笔。之前看到 Kimi 官方微博有说过在研究包月套餐,希望今年能推出吧。如果后面有推出我会在这篇博文里更新相应的使用体验。
【END】